Deforestation Monitoring using Sentinel 2 and xarray
Streamlining Cloud-Based Processing with EOPF and Xarray
Table of contents¶
Introduction¶
Sentinel 2 data is one of the most popular satellite datasets, but it does come with challenges. Cloud-free mosaics have to be constructed often in order to get analysis-ready data. Accessing a lot of data through tiles takes a long time, and getting the data into a format it can be easily analysed in with common Python tools can be a challenge.
In this notebook, we will show how this whole process of getting analysis-ready data into Python can be sped up by using the Copernicus Dataspace Ecosystem and Sentinel Hub APIs. This is being presented by running through a basic deforestation monitoring use-case. The notebook uses the popular xarray Python library to handle the multidimensional data.
Setup¶
Start installing and importing the necessary libraries
!pip install --upgrade zarr xarray daskRequirement already satisfied: zarr in /srv/conda/envs/notebook/lib/python3.12/site-packages (3.0.6)
Requirement already satisfied: xarray in /srv/conda/envs/notebook/lib/python3.12/site-packages (2025.3.1)
Requirement already satisfied: dask in /srv/conda/envs/notebook/lib/python3.12/site-packages (2025.3.0)
Requirement already satisfied: donfig>=0.8 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from zarr) (0.8.1.post1)
Requirement already satisfied: numcodecs>=0.14 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from numcodecs[crc32c]>=0.14->zarr) (0.15.0)
Requirement already satisfied: numpy>=1.25 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from zarr) (2.0.2)
Requirement already satisfied: packaging>=22.0 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from zarr) (24.2)
Requirement already satisfied: typing-extensions>=4.9 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from zarr) (4.12.2)
Requirement already satisfied: pandas>=2.1 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from xarray) (2.2.3)
Requirement already satisfied: click>=8.1 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from dask) (8.1.8)
Requirement already satisfied: cloudpickle>=3.0.0 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from dask) (3.1.1)
Requirement already satisfied: fsspec>=2021.09.0 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from dask) (2024.12.0)
Requirement already satisfied: partd>=1.4.0 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from dask) (1.4.2)
Requirement already satisfied: pyyaml>=5.3.1 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from dask) (6.0.2)
Requirement already satisfied: toolz>=0.10.0 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from dask) (1.0.0)
Requirement already satisfied: deprecated in /srv/conda/envs/notebook/lib/python3.12/site-packages (from numcodecs>=0.14->numcodecs[crc32c]>=0.14->zarr) (1.2.15)
Requirement already satisfied: crc32c>=2.7 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from numcodecs[crc32c]>=0.14->zarr) (2.7.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from pandas>=2.1->xarray) (2.9.0)
Requirement already satisfied: pytz>=2020.1 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from pandas>=2.1->xarray) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from pandas>=2.1->xarray) (2025.1)
Requirement already satisfied: locket in /srv/conda/envs/notebook/lib/python3.12/site-packages (from partd>=1.4.0->dask) (1.0.0)
Requirement already satisfied: six>=1.5 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from python-dateutil>=2.8.2->pandas>=2.1->xarray) (1.17.0)
Requirement already satisfied: wrapt<2,>=1.10 in /srv/conda/envs/notebook/lib/python3.12/site-packages (from deprecated->numcodecs>=0.14->numcodecs[crc32c]>=0.14->zarr) (1.17.2)
import xarray as xr
xr.__version__'2025.3.1'import zarr
zarr.__version__'3.0.6'# Set up a local cluster for distributed computing.
from distributed import LocalCluster
cluster = LocalCluster()
client = cluster.get_client()
clientAccessing the whole dataset¶
We now want to access a time series in order to compute the yearly NDVI index, remove cloudy pixels, and perform other processing steps.
List of available remote files¶
Let’s make a list of available files for this example. In the cell below, we list the available Zarr files in the bucket and print the first five filenames.
import os
from datetime import datetime
import s3fs
bucket = "e05ab01a9d56408d82ac32d69a5aae2a:sample-data"
prefix = "tutorial_data/cpm_v253/"
# Create the S3FileSystem with a custom endpoint
fs = s3fs.S3FileSystem(
anon=True, client_kwargs={"endpoint_url": "https://objectstore.eodc.eu:2222"}
)
# unregister handler to make boto3 work with CEPH
handlers = fs.s3.meta.events._emitter._handlers
handlers_to_unregister = handlers.prefix_search("before-parameter-build.s3")
handler_to_unregister = handlers_to_unregister[0]
fs.s3.meta.events._emitter.unregister(
"before-parameter-build.s3", handler_to_unregister
)
s3path = (
"s3://" + f"{bucket}/{prefix}" + "S2A_MSIL2A_*_*_*_T32UPC_*.zarr"
) # "S2A_MSIL2A_*_N0500_*_T32UPC_*.zarr"
remote_files = fs.glob(s3path)
prefix = "https://objectstore.eodc.eu:2222"
remote_product_path = prefix + remote_files[0]
paths = [f"{prefix}/{f}" for f in remote_files]
paths['https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180601T102021_N0500_R065_T32UPC_20230902T045008.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180604T103021_N0500_R108_T32UPC_20230819T205634.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180611T102021_N0500_R065_T32UPC_20230714T225353.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180614T103021_N0500_R108_T32UPC_20230813T122609.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180621T102021_N0500_R065_T32UPC_20230827T073006.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180624T103021_N0500_R108_T32UPC_20230823T154249.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180701T102021_N0500_R065_T32UPC_20230811T042458.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180704T103021_N0500_R108_T32UPC_20230806T114209.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180711T102021_N0500_R065_T32UPC_20230801T122120.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180714T103021_N0500_R108_T32UPC_20230820T095831.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180721T102021_N0500_R065_T32UPC_20230714T085857.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180724T103021_N0500_R108_T32UPC_20230817T165054.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180731T102021_N0500_R065_T32UPC_20230723T061615.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180803T103021_N0500_R108_T32UPC_20230731T171730.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180810T102021_N0500_R065_T32UPC_20230814T232625.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180813T103021_N0500_R108_T32UPC_20230723T191605.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180820T102021_N0500_R065_T32UPC_20230827T103655.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180823T103021_N0500_R108_T32UPC_20230825T184705.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20180830T102021_N0500_R065_T32UPC_20230801T021046.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190606T102031_N0500_R065_T32UPC_20230712T081022.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190609T103021_N0500_R108_T32UPC_20221220T034347.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190616T102031_N0500_R065_T32UPC_20230609T034634.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190619T103031_N0500_R108_T32UPC_20230805T044707.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190626T102031_N0500_R065_T32UPC_20230707T172528.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190629T103031_N0500_R108_T32UPC_20230722T184033.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190706T102031_N0500_R065_T32UPC_20230719T174117.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190709T103031_N0500_R108_T32UPC_20230721T185041.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190716T102031_N0500_R065_T32UPC_20230605T025414.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190719T103031_N0500_R108_T32UPC_20230625T191021.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190726T102031_N0500_R065_T32UPC_20230509T235130.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190729T103031_N0500_R108_T32UPC_20230719T112519.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190805T102031_N0500_R065_T32UPC_20230719T205706.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190808T103031_N0500_R108_T32UPC_20230808T044628.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190815T102031_N0500_R065_T32UPC_20230720T215905.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190818T103031_N0500_R108_T32UPC_20230719T152637.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190825T102031_N0500_R065_T32UPC_20230721T163630.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20190828T103021_N0500_R108_T32UPC_20230706T202340.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200603T103031_N0500_R108_T32UPC_20230617T065918.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200610T102031_N0500_R065_T32UPC_20230327T090844.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200613T103031_N0500_R108_T32UPC_20230416T172456.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200620T102031_N0500_R065_T32UPC_20230413T205714.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200623T103031_N0500_R108_T32UPC_20230429T181356.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200630T102031_N0500_R065_T32UPC_20230615T121941.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200703T103031_N0500_R108_T32UPC_20230321T201840.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200710T102031_N0500_R065_T32UPC_20230322T183713.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200713T103031_N0500_R108_T32UPC_20230410T210403.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200720T102031_N0500_R065_T32UPC_20230501T182808.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200723T103031_N0500_R108_T32UPC_20230504T135307.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200730T102031_N0500_R065_T32UPC_20230414T031753.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200802T103031_N0500_R108_T32UPC_20230320T212809.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200809T102031_N0500_R065_T32UPC_20230420T170300.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200812T103031_N0500_R108_T32UPC_20230317T231759.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200819T102031_N0500_R065_T32UPC_20230508T065658.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200822T103031_N0500_R108_T32UPC_20230320T145515.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20200829T102031_N0500_R065_T32UPC_20230417T021212.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210605T102021_N0500_R065_T32UPC_20230130T074617.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210608T103021_N0500_R108_T32UPC_20230314T115218.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210615T102021_N0500_R065_T32UPC_20230321T221050.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210618T103021_N0500_R108_T32UPC_20230317T223257.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210625T102021_N0500_R065_T32UPC_20230319T054911.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210628T103021_N0500_R108_T32UPC_20230321T225310.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210705T102031_N0500_R065_T32UPC_20230123T033750.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210708T103031_N0500_R108_T32UPC_20230203T084308.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210715T102031_N0500_R065_T32UPC_20230202T061909.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210718T103031_N0500_R108_T32UPC_20230213T234707.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210725T102031_N0500_R065_T32UPC_20230220T044939.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210728T103031_N0500_R108_T32UPC_20230220T230835.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210804T102031_N0500_R065_T32UPC_20230116T123301.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210807T103031_N0500_R108_T32UPC_20230211T111035.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210814T102031_N0500_R065_T32UPC_20230213T034213.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210817T103021_N0500_R108_T32UPC_20230216T074822.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210824T102031_N0500_R065_T32UPC_20230122T180313.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20210827T103021_N0500_R108_T32UPC_20230218T100102.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220603T102611_N0510_R108_T32UPC_20240714T223933.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220610T101611_N0400_R065_T32UPC_20220610T171812.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220613T103031_N0400_R108_T32UPC_20220613T235021.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220620T102041_N0400_R065_T32UPC_20220620T162319.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220623T103031_N0400_R108_T32UPC_20220623T170319.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220630T102041_N0400_R065_T32UPC_20220630T182013.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220703T102611_N0400_R108_T32UPC_20220703T182512.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220710T101611_N0510_R065_T32UPC_20240712T191654.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220713T103041_N0510_R108_T32UPC_20240704T023004.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220720T101611_N0400_R065_T32UPC_20220720T164302.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220723T102611_N0400_R108_T32UPC_20220723T164456.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220730T101611_N0400_R065_T32UPC_20220730T180956.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220802T102611_N0400_R108_T32UPC_20220802T184101.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220809T102041_N0400_R065_T32UPC_20220809T180703.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220812T103031_N0400_R108_T32UPC_20220812T182800.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220819T101611_N0400_R065_T32UPC_20220819T181701.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220822T102611_N0400_R108_T32UPC_20220822T184205.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20220829T101611_N0400_R065_T32UPC_20220829T163601.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230605T101601_N0509_R065_T32UPC_20230605T162459.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230608T102601_N0509_R108_T32UPC_20230608T181201.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230615T102031_N0509_R065_T32UPC_20230615T193401.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230618T102601_N0509_R108_T32UPC_20230618T181654.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230625T101601_N0509_R065_T32UPC_20230625T161901.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230628T102601_N0509_R108_T32UPC_20230628T180759.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230705T101601_N0509_R065_T32UPC_20230705T163304.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230708T102601_N0509_R108_T32UPC_20230708T181859.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230715T101601_N0509_R065_T32UPC_20230715T164102.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230718T102601_N0509_R108_T32UPC_20230718T181103.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230725T101601_N0509_R065_T32UPC_20230725T161900.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230728T102601_N0509_R108_T32UPC_20230728T164605.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230804T101601_N0509_R065_T32UPC_20230804T180859.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230807T102601_N0509_R108_T32UPC_20230807T164004.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230814T102031_N0509_R065_T32UPC_20230814T155155.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230817T103031_N0509_R108_T32UPC_20230817T155552.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230824T101601_N0509_R065_T32UPC_20230824T162759.zarr',
'https://objectstore.eodc.eu:2222/e05ab01a9d56408d82ac32d69a5aae2a:sample-data/tutorial_data/cpm_v253/S2A_MSIL2A_20230827T102601_N0509_R108_T32UPC_20230827T163659.zarr']Functions to compute cloudless NDVI¶
- Select the classification map variable (scl) to mask invalid pixels (e.g., no data, saturated, cloudy).
- Since the scl variable is available at a different spatial resolution (20m), it is interpolated to 10m resolution.
- Then, compute a cloud-free NDVI using the B04, B03, and B02 bands.
Lets create full timeseries dataset for list of datasets we will use.¶
To create full timeseries, we need to extract the time information. For the moment i do not know how to get time information from metadata, but only from the file name we make a function to get that information from the file name
def extract_time(ds):
date_format = "%Y%m%dT%H%M%S"
filename = ds.encoding["source"]
date_str = os.path.basename(filename).split("_")[2]
time = datetime.strptime(date_str, date_format)
return ds.assign_coords(time=time)%%time
r10m = xr.open_mfdataset(
paths[:],
engine="zarr",
chunks={},
group="/measurements/reflectance/r10m",
concat_dim="time",
combine="nested",
preprocess=extract_time,
decode_cf=False,
)
r10mr10m.b02%%time
r20m_mask_l2a_classification = xr.open_mfdataset(
paths[:],
engine="zarr",
chunks={},
group="conditions/mask/l2a_classification/r20m",
concat_dim="time",
combine="nested",
preprocess=extract_time,
decode_cf=False,
)
r20m_mask_l2a_classificationDesired resolution of our data¶
To speed up processing, we change the data to a coarsen resolution
# Define the resampling factor (10m to 100m = 10x)
factor = 10
r100m = r10m.coarsen(x=factor, y=factor, boundary="trim").mean()
r100mLets start computing¶
Apply mask¶
First compute the mask value in the same resolution as B02, B03, B04, B08 and apply the mask per pixel
%%time
scl_100m = (
r20m_mask_l2a_classification.scl.chunk(chunks={"x": -1, "y": -1}).interp(
x=r100m["x"], y=r100m["y"], method="nearest"
)
# Copy chunking from r10m['b02'] to cls_r10m
.chunk(r100m["b02"].chunks)
)
scl_100m%%time
def validate_scl(scl):
invalid = [0, 1, 3, 7, 8, 9, 10] # NO_DATA, SATURATED, CLOUD, etc.
return ~scl.isin(invalid)
valid_mask = validate_scl(scl_100m) # Boolean mask (10980x10980)
valid_mask%%time
# Apply mask per pixel, keep spatial dims
valid_r100m = r100m.where(valid_mask)
valid_r100mApply scaling factor and add offset¶
%%time
b04 = (
valid_r100m["b04"] * valid_r100m["b04"].attrs["_eopf_attrs"]["scale_factor"]
+ valid_r100m["b04"].attrs["_eopf_attrs"]["add_offset"]
)
b08 = (
valid_r100m["b08"] * valid_r100m["b08"].attrs["_eopf_attrs"]["scale_factor"]
+ valid_r100m["b08"].attrs["_eopf_attrs"]["add_offset"]
)
ndvi = (b08 - b04) / (b08 + b04) # Per-pixel NDVI
ndvivalid_r100m%%time
# Stack bands and NDVI, scale to match Sentinel Hub
# Not sure if we need to concat in this way? can keep it as data arrays in the dataset may be here??
scale = xr.concat(
[valid_r100m["b04"], valid_r100m["b03"], valid_r100m["b02"], ndvi], dim="bands"
)
cloudless_ndvi = scale.rename("data").assign_coords(bands=["b04", "b03", "b02", "ndvi"])
cloudless_ndvicloudless_ndvi.sel(time=datetime(2018, 7, 11), method="nearest")Subset spatially¶
It is always good practice to select data over the area of interest, as this can significantly reduce memory usage when computing NDVI or applying any processing.
from datetime import datetime
from pathlib import Path
import geopandas as gpd
import matplotlib.colors as mcolors
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
import numpy as np
import requests
import xarray as xr
from ipyleaflet import Map, Polygon
from shapely import geometryepsg = 32632
bbox = [10.633501, 51.611195, 10.787234, 51.698098]
bbox_coords = [10.633501, 51.611195, 10.787234, 51.698098]
center = ((bbox[1] + bbox[3]) / 2.0, (bbox[0] + bbox[2]) / 2.0)
m = Map(center=center, zoom=11)
# Create polygon from lists of points
polygon = Polygon(
locations=[
(bbox[1], bbox[0]),
(bbox[3], bbox[0]),
(bbox[3], bbox[2]),
(bbox[1], bbox[2]),
],
color="green",
fill_color="green",
)
# Add the polygon to the map
m.add(polygon)
mbbox_polygon = geometry.box(*bbox)
polygon = gpd.GeoDataFrame(index=[0], crs="epsg:4326", geometry=[bbox_polygon])
bbox_reproj = polygon.to_crs("epsg:" + str(epsg)).geometry.values[0].bounds
bbox_reproj(612890.0057926236, 5719059.568597787, 623750.1130221735, 5728972.640384748)x_slice = slice(bbox_reproj[0], bbox_reproj[2]) # ~1000 pixels
y_slice = slice(bbox_reproj[3], bbox_reproj[1]) # ~1000 pixels
# region = cloudless_ndvi.sel(time="20180601T102021", x=x_slice, y=y_slice)
region = cloudless_ndvi.sel(x=x_slice, y=y_slice).chunk(
{"time": "auto", "y": "auto", "x": "auto"}
)
region = region.to_dataset()
region.data_vars.items()ItemsView(Data variables:
data (bands, time, y, x) float64 38MB dask.array<chunksize=(1, 109, 100, 109), meta=np.ndarray>)scaling_factor_b04 = r100m["b04"].attrs["_eopf_attrs"]["scale_factor"]
add_offset_b04 = r100m["b04"].attrs["_eopf_attrs"]["add_offset"]%%time
rgb = (
region.sel(time="20180601", method="nearest").sel(bands=slice("b04", "b02"))
* scaling_factor_b04
+ add_offset_b04
)
rgb = (rgb - 0.02) / (0.35 - 0.02) # Stretch 0.02-0.35 to 0-1
rgb = rgb.clip(0, 1)
rgb.load()%%time
ndvi = region.sel(time="20180601", method="nearest").sel(bands="ndvi")
ndvi.load()fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
fig.suptitle("Date - 20180601T102021\n")
# First subplot
rgb.data.plot.imshow(
ax=ax1,
rgb="bands",
extent=(x_slice.start, x_slice.stop, y_slice.start, y_slice.stop),
)
ax1.set_title("RGB (Enhanced)")
# Second plot
ndvi_plot = ndvi.data.plot(ax=ax2, cmap="Greens", vmin=-1, vmax=1, add_colorbar=False)
ax2.set_title("NDVI")
# Add color bar on the right
fig.subplots_adjust(right=0.8)
cbar_ax = fig.add_axes([0.85, 0.15, 0.05, 0.7])
fig.colorbar(ndvi_plot, cax=cbar_ax)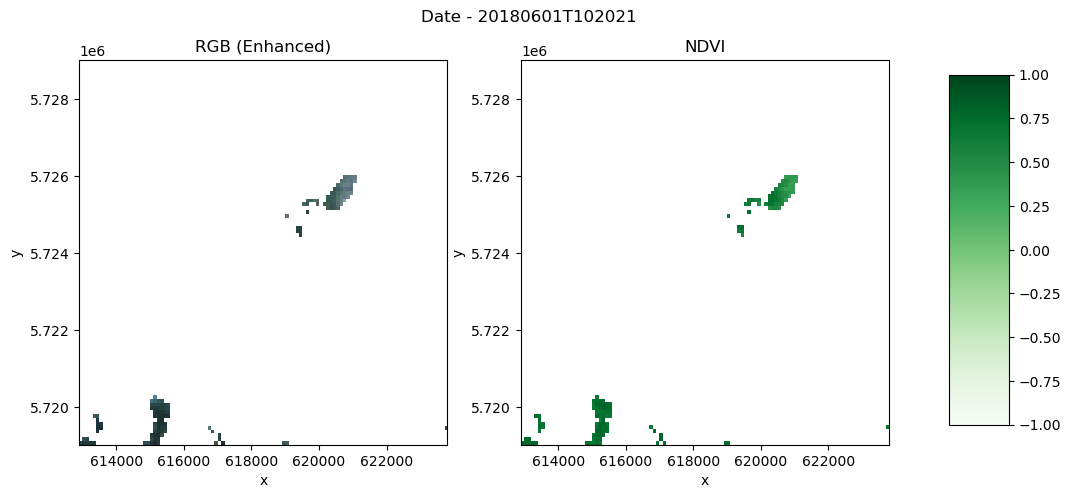
Yearly mean¶
# Group by year and compute mean
# yearly_da = bbox_reproj.groupby("time.year").mean(dim="time", skipna=True)
yearly_da = (
cloudless_ndvi.sel(x=x_slice, y=y_slice)
.groupby("time.year")
.mean(dim="time", skipna=True)
)
yearly_daVisualize NDVI for 2018¶
def plot_rgb_ndvi(dset, year, scaling, add_offset, x_slice, y_slice):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
fig.suptitle("Date - " + str(year) + "\n")
# First subplot
rgb = dset.sel(bands=slice("b04", "b02")) * scaling_factor_b04 + add_offset_b04
rgb = (rgb - 0.02) / (0.35 - 0.02) # Stretch 0.02-0.35 to 0-1
rgb = rgb.clip(0, 1) # Clip to valid range
rgb.plot.imshow(
ax=ax1,
rgb="bands",
extent=(x_slice.start, x_slice.stop, y_slice.start, y_slice.stop),
)
ax1.set_title("RGB (Enhanced)")
# Second plot
ndvi_plot = dset.sel(bands="ndvi").plot(
ax=ax2, cmap="Greens", vmin=-1, vmax=1, add_colorbar=False
)
ax2.set_title("NDVI")
# Add color bar on the right
fig.subplots_adjust(right=0.8)
cbar_ax = fig.add_axes([0.85, 0.15, 0.05, 0.7])
fig.colorbar(ndvi_plot, cax=cbar_ax)year = 2018
# Select year (descending y)
year = 2018 # Adjust if more years
region = yearly_da.sel(year=year, x=x_slice, y=y_slice)
plot_rgb_ndvi(region, year, scaling_factor_b04, add_offset_b04, x_slice, y_slice)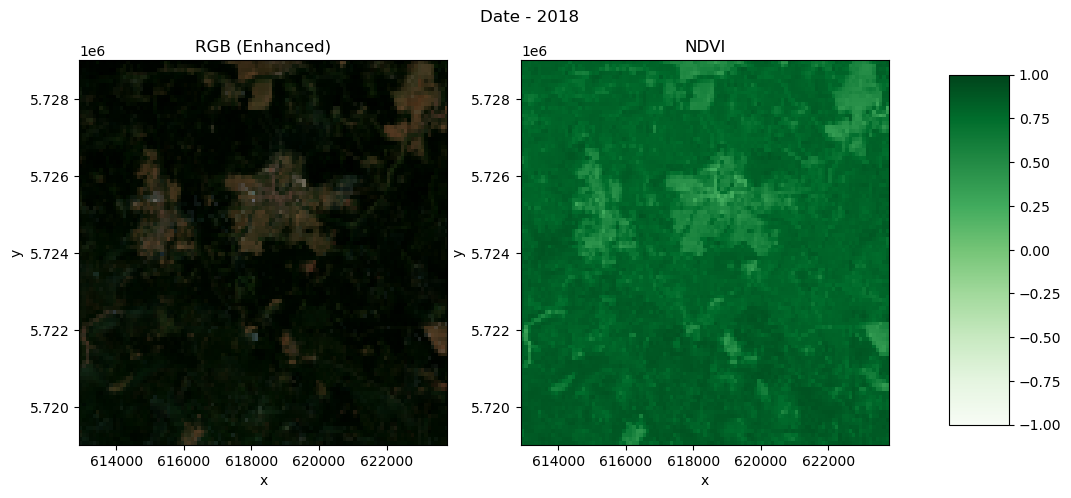
Visualise NDVI from 2018 to 2023¶
# Select NDVI and plot per year (smaller region for speed)
ndvi_yearly = yearly_da.sel(bands="ndvi", x=x_slice, y=y_slice).sel(
year=slice(2018, 2023)
)
ndvi_yearly.plot(
cmap="PRGn", x="x", y="y", col="year", col_wrap=2, vmin=-1, vmax=1, figsize=(10, 15)
)<xarray.plot.facetgrid.FacetGrid at 0x7e8453462480>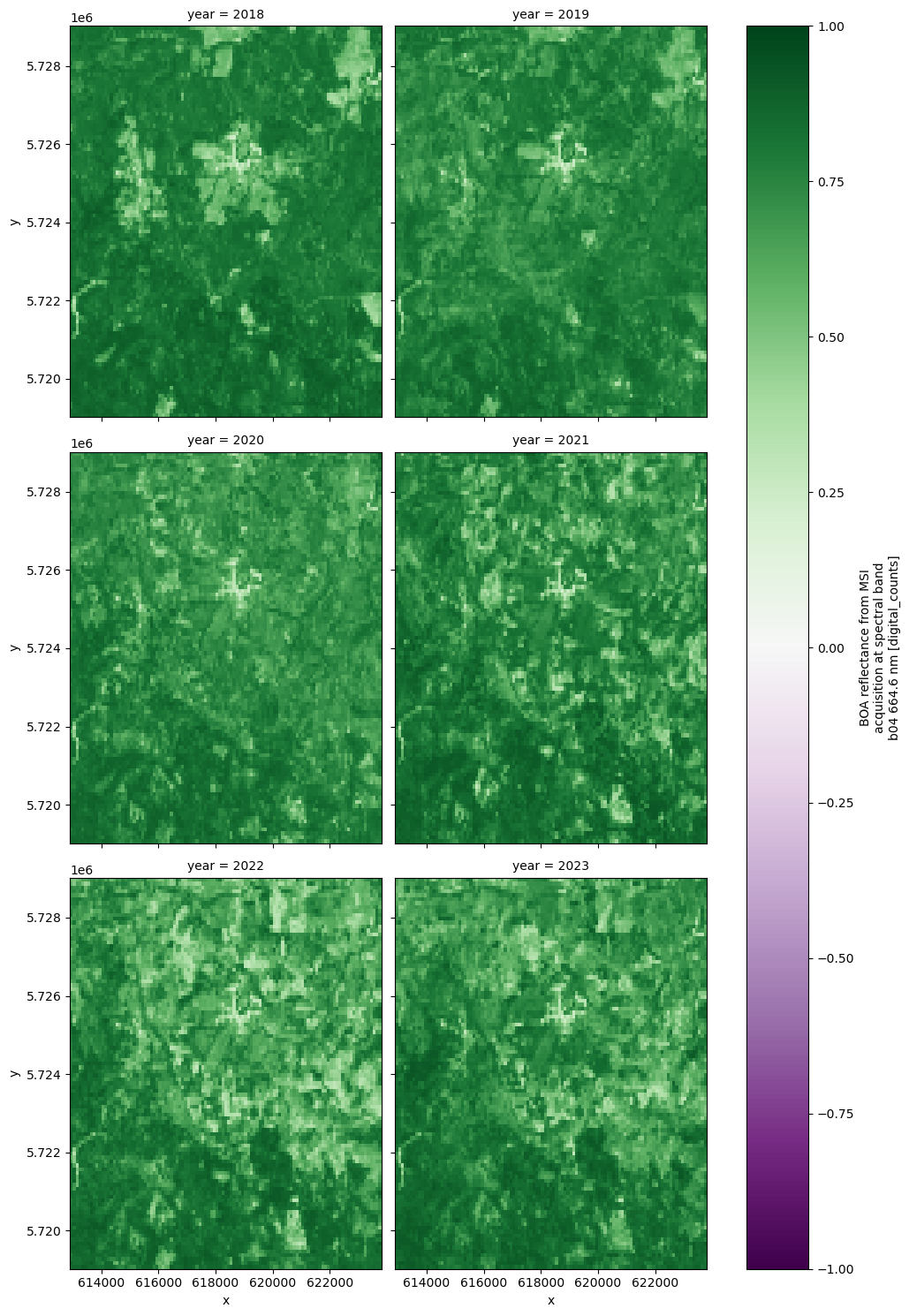
Create Xarray with NDVI and corresponding bands as variables¶
Rather than organizing the Xarray as a single DataArray with all the bands and NDVI as coordinates, we can structure it so that the coordinates represent the geographical extent of the area (x, y), and the bands become separate variables.
We create a new Xarray Dataset below with bands and NDVI as variables
ndvi_ds = xr.Dataset(
{
"NDVI": yearly_da.sel(bands="ndvi").drop_vars("bands"),
"B04": yearly_da.sel(bands="b04").drop_vars("bands"),
"B03": yearly_da.sel(bands="b03").drop_vars("bands"),
"B02": yearly_da.sel(bands="b02").drop_vars("bands"),
}
)
ndvi_dsSaving yearly NDVI into local Zarr¶
- Prepare dataset to be saved with a particular attention to chunks
region = region.to_dataset()
region.data_vars.items()
region = region.chunk({"bands": 1, "y": 50, "x": 55})
print(region)
print(region["data"].chunks)<xarray.Dataset> Size: 351kB
Dimensions: (x: 109, y: 100, bands: 4)
Coordinates:
* x (x) float64 872B 6.13e+05 6.13e+05 ... 6.236e+05 6.238e+05
* y (y) float64 800B 5.729e+06 5.729e+06 ... 5.719e+06 5.719e+06
* bands (bands) <U4 64B 'b04' 'b03' 'b02' 'ndvi'
year int64 8B 2018
Data variables:
data (bands, y, x) float64 349kB dask.array<chunksize=(1, 50, 55), meta=np.ndarray>
((1, 1, 1, 1), (50, 50), (55, 54))
%%time
from zarr.codecs import BloscCodec
compressor = BloscCodec(cname="zstd", clevel=3, shuffle="bitshuffle", blocksize=0)
encoding = {}
for var in region.data_vars:
encoding[var] = {"compressors": [compressor]}
for coord in region.coords:
encoding[coord] = {"compressors": [compressor]}
region.to_zarr("ndvi_region.zarr", zarr_format=3, encoding=encoding, mode="w")/srv/conda/envs/notebook/lib/python3.12/site-packages/zarr/codecs/vlen_utf8.py:44: UserWarning: The codec `vlen-utf8` is currently not part in the Zarr format 3 specification. It may not be supported by other zarr implementations and may change in the future.
return cls(**configuration_parsed)
/srv/conda/envs/notebook/lib/python3.12/site-packages/zarr/core/array.py:3989: UserWarning: The dtype `<U4` is currently not part in the Zarr format 3 specification. It may not be supported by other zarr implementations and may change in the future.
meta = AsyncArray._create_metadata_v3(
/srv/conda/envs/notebook/lib/python3.12/site-packages/zarr/codecs/vlen_utf8.py:44: UserWarning: The codec `vlen-utf8` is currently not part in the Zarr format 3 specification. It may not be supported by other zarr implementations and may change in the future.
return cls(**configuration_parsed)
/srv/conda/envs/notebook/lib/python3.12/site-packages/zarr/api/asynchronous.py:203: UserWarning: Consolidated metadata is currently not part in the Zarr format 3 specification. It may not be supported by other zarr implementations and may change in the future.
warnings.warn(
CPU times: user 3.28 s, sys: 704 ms, total: 3.98 s
Wall time: 11.3 s
<xarray.backends.zarr.ZarrStore at 0x7e846a0bf130>Analysis¶
For analysis the first step is to classify pixels as forest. In our case we will just do a simple thresholding classification where we classify everything above a certain threshold as forest. This isn’t the best approach for classifying forest, since agricultural areas can also easily reach very high NDVI values. A better approach would be to classify based on the temporal signature of the pixel.
However, for this basic analysis, we stick to the simple thresholding approach.
In this case we classify everything above an NDVI of 0.7 as forest. This calculated forest mask is then saved to a new Data Variable in the xarray dataset:
ndvi_ds["FOREST"] = ndvi_ds.NDVI > 0.7With this forest mask we can already do a quick preliminary analysis to plot the total forest area over the years.
To do this we sum up the pixels along the x and y coordinate but not along the time coordinate. This will leave us with one value per year representing the number of pixels classified as forest. We can then calculate the forest area by multiplying the number of forest pixels by the resolution.
def to_km2(dataarray, resolution):
# Calculate forest area
return dataarray * np.prod(list(resolution)) / 1e6resolution = (100, 100)
forest_pixels = ndvi_ds.sel(x=x_slice, y=y_slice).FOREST.sum(["x", "y"])
forest_area_km2 = to_km2(forest_pixels, resolution)
forest_area_km2forest_area_km2.load()forest_area_km2# forest_area_km2.sel(year=slice(2018, 2023)).plot()
forest_area_km2.plot()
plt.title("Forest Cover")
plt.ylabel("Forest Cover [km²]")
plt.ylim(0);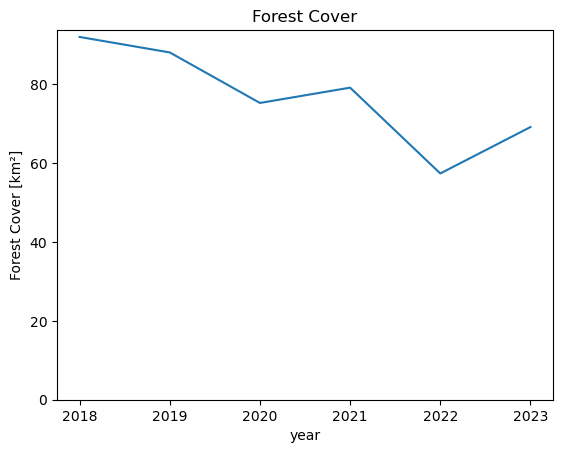
We can see that the total forest area in this AOI decreased from around 80 km² in 2018 to only around 50 km² in 2023.
The next step is to make change maps from year to year. To do this we basically take the difference of the forest mask of a year with its previous year.
This will result in 0 value where there has been no change, -1 where forest was lost and +1 where forest was gained.
# Make change maps of forest loss and forest gain compared to previous year
# 0 - 0 = No Change: 0
# 1 - 1 = No Change: 0
# 1 - 0 = Forest Gain: 1
# 0 - 1 = Forest Loss: -1
# Define custom colors and labels
colors = ["darkred", "white", "darkblue"]
labels = ["Forest Loss", "No Change", "Forest Gain"]
# Create a colormap and normalize it
cmap = mcolors.ListedColormap(colors)
norm = plt.Normalize(-1, 1) # Adjust the range based on your dataUse 2022 as plot_year¶
plot_year = 2022
ndvi_ds["CHANGE"] = ndvi_ds.FOREST.astype(int).diff("year", label="upper")ndvi_ds["CHANGE"].compute()Visualize the differences¶
ndvi_ds.CHANGE.sel(year=plot_year).plot(cmap=cmap, norm=norm, add_colorbar=False)
# Create a legend with string labels
legend_patches = [
mpatches.Patch(color=color, label=label) for color, label in zip(colors, labels)
]
plt.legend(handles=legend_patches, loc="lower left")
plt.title(f"Forest Change Map {plot_year}");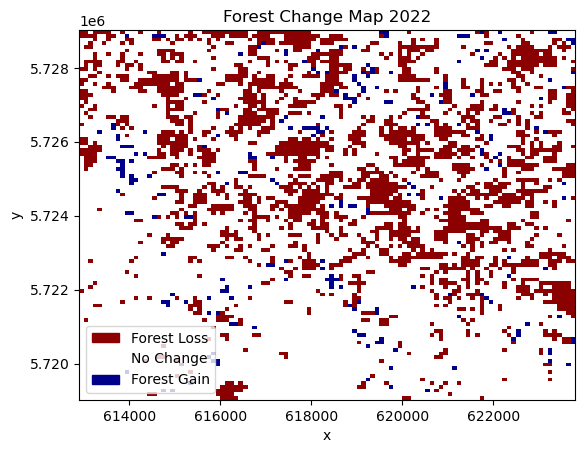
Here, we can see the spatial distribution of areas affected by forest loss. In the displayed change from 2021 to 2022, most of the forest loss happened in the northern part of the study area, while the southern part lost comparatively less forest.
To get a feel for the loss per year, we can cumulatively sum up the lost areas over the years. This should basically follow the same trends as the earlier plot of total forest area.
# Forest Loss per Year
forest_loss = (ndvi_ds.CHANGE == -1).sum(["x", "y"])
forest_loss_km2 = to_km2(forest_loss, resolution)
forest_loss_km2.cumsum().plot()
plt.title("Cumulative Forest Loss")
plt.ylabel("Forest Loss [km²]");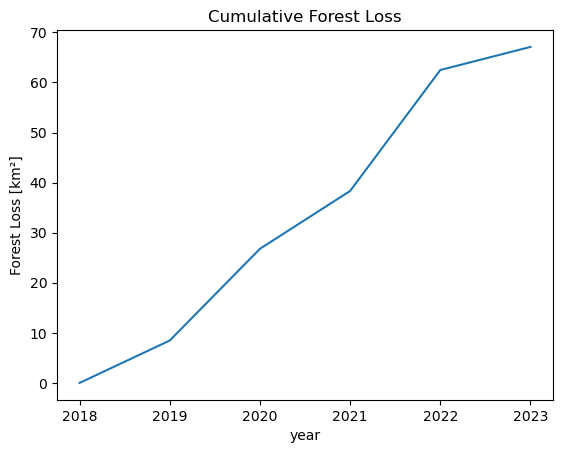
We can see that there have been two years with particularly large amounts of lost forest area. From 2019-2020 and with by far the most lost area between 2021 and 2022.
Validation¶
Finally, we want to see how accurate our data is compared to the widely used Hansen Global Forest Change data. In a real scientific scenario, we would use Ground Truth data to assess the accuracy of our classification. In this case we use the Global Forest Change data in place of Ground Truth data, just to show how an accuracy assessment can be done. The assessment we are doing only shows how accurately we replicate the Global Forest Change data, however we will not know if our product is more or less accurate. For a more accurate assessment, actual Ground Truth data is required.
First we download the Global Forest Change Data here and open it using xarray.
data_path = Path("./data/")
data_path.mkdir(parents=True, exist_ok=True)
hansen_filename = "Hansen_GFC-2022-v1.10_lossyear_60N_010E.tif"
comp_data = data_path / hansen_filename
with comp_data.open("wb") as fs:
hansen_data = requests.get(
f"https://storage.googleapis.com/earthenginepartners-hansen/GFC-2022-v1.10/{hansen_filename}"
)
fs.write(hansen_data.content)import matplotlib.pyplot as plt
import rioxarray
target_epsg = epsg
# Open the file (replace 'comp_data' with your raster file path)
ground_truth = (
rioxarray.open_rasterio(comp_data) # Replace with your file path
.rio.clip_box(
minx=bbox_coords[0],
miny=bbox_coords[1],
maxx=bbox_coords[2],
maxy=bbox_coords[3],
)
.rio.reproject(target_epsg)
.sel(band=1)
.where(lambda gt: gt < 100, 0) # Fill no-data (values > 100) with 0
)
# Plot
ground_truth.plot(levels=range(25), cbar_kwargs={"label": "Year of Forest Loss"})
plt.title("Global Forest Watch Data")
plt.show()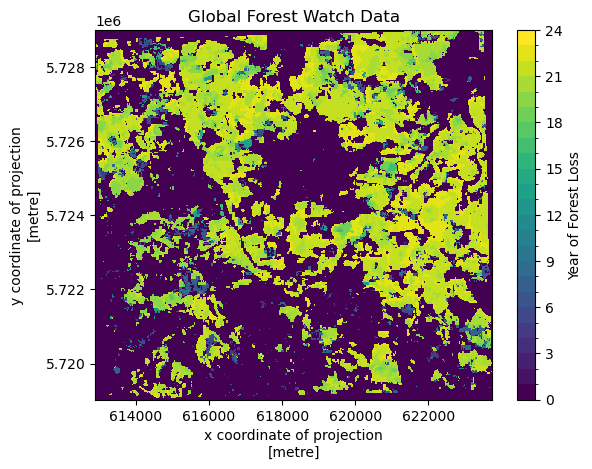
The data shows in which year forest was first lost. To compare with our own data, we need to add the data to our dataset. To do this the data needs to have the same coordinates. This can be achieved with .interp_like(). This function interpolates the data to match up the coordinates of another dataset.
In this case we chose the interpolation method nearest since it is categorical data.
ndvi_ds["GROUND_TRUTH"] = ground_truth.interp_like(ndvi_ds, method="nearest").astype(
int
)
ndvi_dsThe ground truth data saves the year when deforestation was first detected for a pixel in a single raster. To do this, it encodes the year of forest loss as an integer, giving the year. So, an integer 21 means the pixel was first detected as deforested in 2021, whereas a value of 0 means that deforestation was never detected.
Currently our classification saves the deforestation detection in multiple rasters, one for each year. To get our data into a format that is similar to our comparison data we need to convert our rasters for each time step into a single one.
To do this we first assign all pixels which were detected as deforestation (CHANGE == -1) to the year in which the deforestation was detected (lost_year). Then we compute over our time-series the first occurence of deforestation (equivalent to the first non-zero value) per pixel. This is then saved in a new data variable.
# convert lost forest (-1) into the year it was lost
lost_year = (ndvi_ds.CHANGE == -1) * ndvi_ds.year % 100
first_nonzero = (lost_year != 0).argmax(axis=0).compute()
ndvi_ds["LOST_YEAR"] = lost_year[first_nonzero]
ndvi_ds.LOST_YEAR.plot(levels=range(25), cbar_kwargs={"label": "Year of Forest Loss"})
plt.title("Classification Forest Loss Year");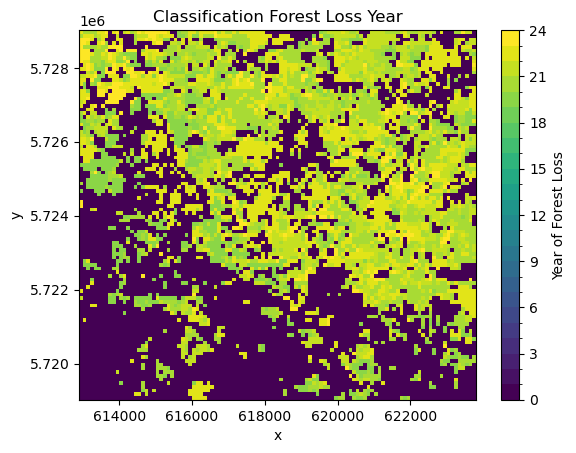
Comparing this visually to the Global Forest Watch data, allows us to do some initial quality assessment. We can see definite differences between the two datasets. The Global Forest Watch data has much more clearly defined borders. In general, our classification seems to overestimate deforestation. However, the general pattern of forest loss is the same in both. Most of the deforestation is in the north of the study area, with less forest loss in the south.
There are a few reasons for those differences. The main difference has to be in our much more simple approach to forest classification and change detection. It is expected that our approach will lead to large amounts of commission errors since changes are only confirmed using a single observation. It however can also lead to a lot of omission errors since the NDVI thresholding might classify highly productive non-forest areas as forest due to their high NDVI values.
However, there are also some systematic differences. Our algorithm looks at differences between the middle of the years, which means that some changes can happen at the end of the growing year which will be detected first in the next year whereas the Global Forest Watch dataset will detect it in the correct (earlier) year.
ndvi_ds.GROUND_TRUTH.plot(
levels=range(25), cbar_kwargs={"label": "Year of Forest Loss"}, cmap="viridis"
)
plt.title("Global Forest Watch - Interpolated");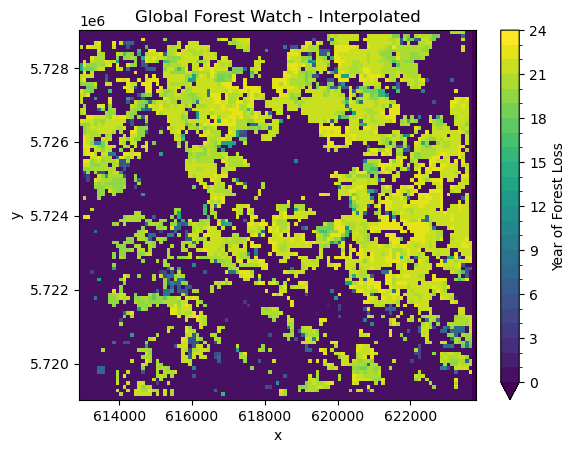
Finally, we can also calculate an accuracy score. This is a score from 0-1, where values close to 0.5 basically mean that the classification is random, and values close to 1 mean that most of the values of our comparison data and classification data match.
First, we look at the overall accuracy of forest loss over the entire period from 2018 to 2023.
from sklearn.metrics import accuracy_score
score = accuracy_score(
(ndvi_ds.LOST_YEAR > 18).values.ravel(), (ndvi_ds.GROUND_TRUTH > 18).values.ravel()
)
print(f"The overall accuracy of forest loss detection is {score:.2f}.")The overall accuracy of forest loss detection is 0.76.
As expected from the visual interpretation, with an accuracy of 0.76, our product differs quite a lot compared to the Global Forest Watch data. From this we do not know for sure that our product is less accurate compared to the actual forest loss patterns observed on the ground. We only know that it is different to the Global Forest Watch product. It might be more or less accurate.
However, because of the simplicity of our algorithm, it is safe to assume that our output is less accurate.
Summary¶
This notebook showed how to efficiently access data stored on the Copernicus Dataspace Ecosystem using the Sentinel Hub APIs. This includes generating cloud-free mosaics and calculating spectral indices in the cloud.
It also showed how to import this data using xarray and carry out a basic multi-temporal detection of forest loss.
This notebook should serve as a starting point for your own analysis using the powerful Python Data Analysis ecosystem and leveraging the Copernicus Data Space Ecosystem APIs for quick satellite data access.
client.close()