📡🌍 BiDS’25 — EO4EU Tutorial#
![]()
EO4EU Objectives#
AI-augmented ecosystem for Earth Observation data accessibility with Extended reality User Interfaces for Service and data exploitation, or EO4EU, is a European Commission funded innovation project which aims at creating an advanced platform for searching, discovering, processing and analyzing EO data. The platform leverages machine learning to support handling of the characteristically-large volume of EO data as well as a combination of cloud computing infrastructure and pre-exascale high-performance computing to manage processing workloads.
The EO4EU Platform allows for searching, discovering processing and analyzing EO data and is based on a series of innovative technologies which allow to:
Access EO data from different sources (e.g., Copernicus, Galileo, ECMWF).
Support a sophisticated representation of data through a semantic-enhanced Knowledge Graph.
Use Machine Learning from marketplace to EO data processing.
Visualize EO data through easy-to-use graphical interfaces and Extended Reality applications.
EO4EU Architecture#
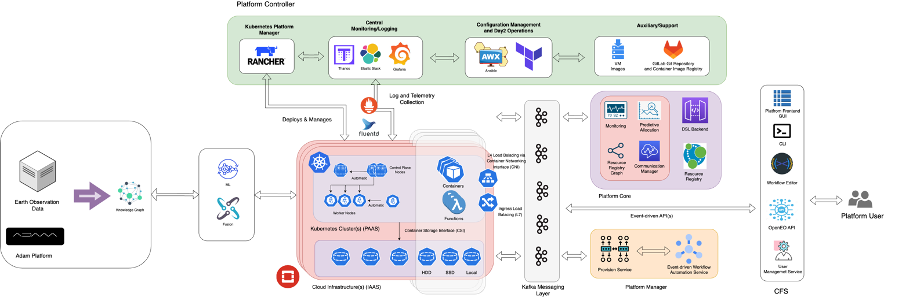
EO4EU Infrastructure#
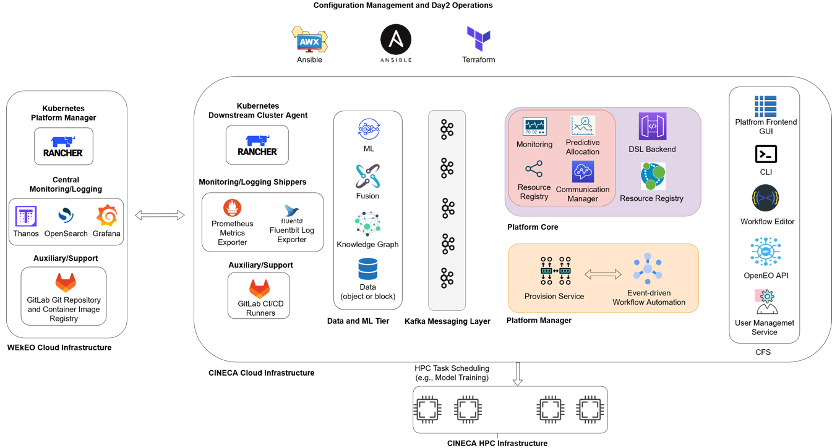
Check out the content pages bundled with this sample book to see more.
EO4EU Use Cases#
EO for Personalized Health Care: to expand mobile allergy and airbrone hazards forecasting.
Food Security: to improve the adaptability of food production using EO4EU for live climate data tracking and analysis.
Soil Erosion: to integrate rainfall datasets through EO4EU to assess soil suspectibility to water erosion.
Civil Protection: to improve disaster and calamity prevention and response using EO datasets.
Ocean Monitoring: to optimize shipping industry travel time across different oceans considering live weather data.
Forest Ecosystem: to improve forest productivity using EO4EU to simulate water, energy and carbon fluxes.
Environmental Pests: to assess and predict the impact of locust plague.
For more information visit EO4EU website
📡🌍 BiDS’25 — Lightweight Masked Autoencoder Architecture for Earth Observation#
This notebook explores a metadata-aware lightweight Mixutre-of-Experts Masked Autoencoder (MOE-MAE) architecture for Earth Observation (EO) data.
📑 Contents#
1. Overview#
Lightweight metadata-aware MOE-MAE
Pretraining strategy
Comparison with larger MAE architectures
2. Embedding Exploration#
Generate embeddings of the EuroSAT-Landsat dataset using MoE-MAE
Visualize the learned feature space with t-SNE
Highlight different sample categories from EuroSAT-LS
3. Expert Specialization#
Investigate how individual experts specialize
4. Search by Image#
Perform image retrieval using embeddings
Use ChromaDB for efficient similarity search
1) Overview#
Model Design#
Architecture: Compact Vision Transformer with Mixture-of-Experts (MoE).
Parameters: ~2.5M total (encoder ~2.3M).
Model |
Type |
Parameters |
|---|---|---|
ResNet-18 (ImageNet / SSL4EO-L) |
CNN |
~11M |
ResNet-50 (ImageNet / SSL4EO-L) |
CNN |
~25M |
ViT-S/16 (ImageNet / SSL4EO-L) |
Transformer |
~22M |
DOFA-B/16 |
Transformer |
~111M |
DOFA-L/16 |
Transformer |
~330M |
Satlas Swin V2-B |
Transformer |
~88M |
Prithvi-EO-100M |
Transformer |
~100M |
Prithvi-EO-2.0 300M |
Transformer |
~300M |
Prithvi-EO-2.0 600M |
Transformer |
~600M |
Ours: MoE-MAE |
Transformer (MoE) |
~2.5M |
Core ideas:
Sparse expert routing: Tokens routed to a small subset of SwiGLU experts using NoisyTop-k gating.
Geo-temporal conditioning: Latitude, longitude, week-of-year, and hour-of-day encoded as sinusoidal (sin, cos) pairs → projected into embedding space → added as metadata tokens.
Grouped Query Attention (GQA): Efficient multi-head attention variant.
Lightweight decoder: Two MoE transformer layers with reduced hidden size.

Pretraining Objective#
The model is trained using a self-supervised reconstruction-based objective:
Masked patch reconstruction
Loss applied to masked patches only.\[ L_{\text{masked}} = \frac{1}{|M|} \sum_{i \in M} \| \hat{x}_i - x_i \|^2 \]Auxiliary reconstruction on visible patches
$\( L_{\text{unmasked}} = \frac{1}{|V|} \sum_{i \in V} \| \hat{x}_i - x_i \|^2 \)$MoE regularization (load balancing)
Ensures balanced expert usage via coefficient-of-variation penalties.
Final loss function: $\( L = L_{\text{masked}} + \alpha L_{\text{unmasked}} + \beta L_{\text{MoE}} \)$
Training Setup#
Dataset: BigEarthNet-Landsat (BEN-LS) Training Split, ~320k samples, 7 spectral bands.
Masking ratio: 75%.
Epochs: 500.
Batch size: 128.
Optimizer: AdamW.
Learning rate schedule:
Base LR = 3e-4.
Warmup for 5% of epochs.
Cosine decay to 0.
Weight decay: 0.05.
@misc{albughdadi2025lightweightmetadataawaremixtureofexpertsmasked,
title={Lightweight Metadata-Aware Mixture-of-Experts Masked Autoencoder for Earth Observation},
author={Mohanad Albughdadi},
year={2025},
eprint={2509.10919},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.10919},
}
Install requirements#
# ! pip install geo_moe_mae/requirements.txt
! pip install plotly==6.2.0 chromadb==1.0.21
! git lfs install
Download EuroSAT-LANDSAT dataset from HuggingFace#
! git clone https://huggingface.co/datasets/isaaccorley/eurosat-l
fatal: destination path 'eurosat-l' already exists and is not an empty directory.
! bsdtar -xf eurosat-l/eurosat-l.zip -C eurosat-l
Clone Metadata-Aware MOE-MAE from Github#
! git clone https://github.com/AlbughdadiM/geo-moe-mae.git
Cloning into 'geo-moe-mae'...
remote: Enumerating objects: 495, done.
remote: Counting objects: 100% (495/495), done.
remote: Compressing objects: 100% (270/270), done.
remote: Total 495 (delta 222), reused 489 (delta 216), pack-reused 0 (from 0)
Receiving objects: 100% (495/495), 34.00 MiB | 39.07 MiB/s, done.
Resolving deltas: 100% (222/222), done.
Get EuroSAT-LANDSAT test split embeddings#
! wget https://object-store.os-api.cci1.ecmwf.int/MoBucket/BiDS2025/x_y_test_eurosat_ls.npz
--2025-09-24 11:23:59-- https://object-store.os-api.cci1.ecmwf.int/MoBucket/BiDS2025/x_y_test_eurosat_ls.npz
Resolving object-store.os-api.cci1.ecmwf.int (object-store.os-api.cci1.ecmwf.int)... 136.156.128.3
Connecting to object-store.os-api.cci1.ecmwf.int (object-store.os-api.cci1.ecmwf.int)|136.156.128.3|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 326700510 (312M) [application/zip]
Saving to: ‘x_y_test_eurosat_ls.npz’
x_y_test_eurosat_ls 100%[===================>] 311.57M 92.0MB/s in 3.6s
2025-09-24 11:24:03 (87.4 MB/s) - ‘x_y_test_eurosat_ls.npz’ saved [326700510/326700510]
Import libraries#
import sys
sys.path.append("./geo-moe-mae")
import os
import shutil
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
import numpy as np
import math
from torch.utils.data import Subset
import chromadb
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.express as px
from models.moe_mae import MOEMAE, build_model
from datasets.eurosat import EuroSATDatasetLS
from utils.data_config import BigEarthNetInfo
from utils.data_utils import load_model
from transformation.transformer import ToFloat, ZScoreNormalize
from utils.analysis_utils import layer_report_simple
Get accelration device if available#
device = (
"cuda"
if torch.cuda.is_available()
else "mps" if torch.backends.mps.is_available() else "cpu"
)
print(f"Using device: {device}")
Using device: mps
Initialize Metadata-Aware MoE-MAE model#
model_size = "S"
img_size = 40
patch_size = 4
in_channels = 7
checkpoint_path = "./geo-moe-mae/weights/moe_mae_bigearthnet_ls/pretrained_S_best.pth"
encoder = build_model(
size=model_size,
img_size=img_size,
patch_size=patch_size,
in_chans=in_channels,
)
model = MOEMAE(encoder).to(device)
model = load_model(model,checkpoint_path,device)
encoder = model.encoder
encoder.eval();
Set data path#
data_txt_test = "./eurosat-l/eurosat-test.txt"
data_path = "./eurosat-l/eurosat-l"
save_path = "./eurosat-l"
label_class = ['AnnualCrop',
'Forest',
'HerbaceousVegetation',
'Highway',
'Industrial',
'Pasture',
'PermanentCrop',
'Residential',
'River',
'SeaLake']
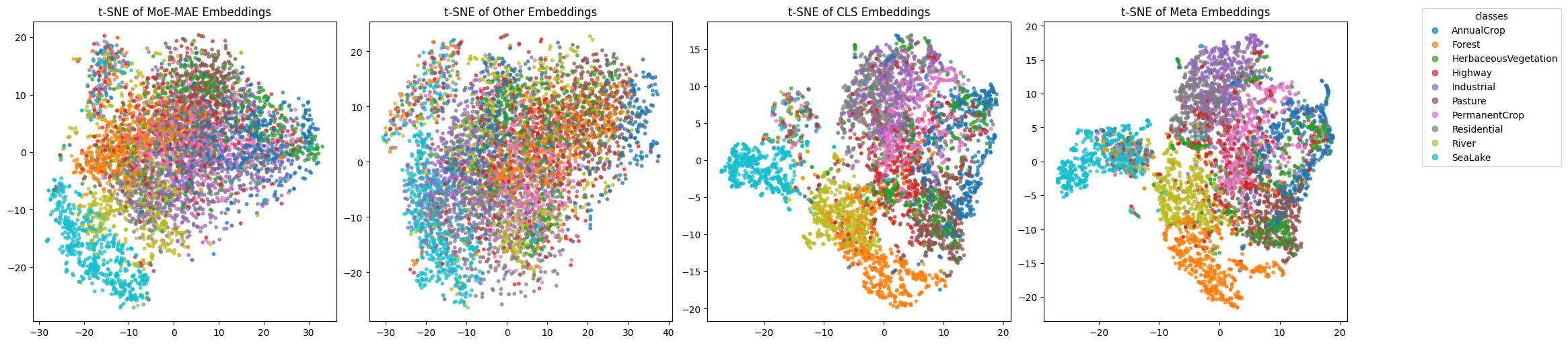
2) Embedding Exploration using t-SNE#
Apply t-SNE and visualize with the dataset labels#
npz_path_test = "x_y_test_eurosat_ls.npz"
test_embeddings = np.load(npz_path_test)
x_test, y_test= (
test_embeddings["x_test"],
test_embeddings["y_test"]
)
meta_tokens = x_test[:, 0:576]
cls_token = x_test[:, 576:720]
other_tokens = x_test[:, 720:]
labels = np.argmax(y_test, axis=1)
print (cls_token.shape)
print (other_tokens.shape)
print (x_test.shape)
print (labels.shape)
(5400, 144)
(5400, 14400)
(5400, 15120)
(5400,)
t-SNE on all tokens#
tsne = TSNE(n_components=3, random_state=42, perplexity=30)
emb_3d = tsne.fit_transform(x_test)
t-SNE on all tokens other than metadata and cls token#
tsne = TSNE(n_components=3, random_state=42, perplexity=30)
emb_3d_other = tsne.fit_transform(other_tokens)
t-SNE on CLS tokens#
tsne = TSNE(n_components=3, random_state=42, perplexity=30)
emb_3d_cls = tsne.fit_transform(cls_token)
t-SNE on metadata tokens#
tsne = TSNE(n_components=3, random_state=42, perplexity=30)
emb_3d_meta = tsne.fit_transform(meta_tokens)
Plot the results#
fig, axes = plt.subplots(1, 4, figsize=(20, 5), constrained_layout=True)
embeddings = [emb_3d, emb_3d_other, emb_3d_cls, emb_3d_meta]
titles = ["t-SNE of MoE-MAE Embeddings",
"t-SNE of Other Embeddings",
"t-SNE of CLS Embeddings",
"t-SNE of Meta Embeddings"]
for ax, emb, title in zip(axes, embeddings, titles):
scatter = ax.scatter(
emb[:, 0], emb[:, 1],
c=labels, cmap="tab10", s=10, alpha=0.7
)
ax.set_title(title)
# Create a single legend for all subplots
handles, cls_labels = scatter.legend_elements(num=len(label_class))
fig.legend(handles, label_class, title="classes", bbox_to_anchor=(1.05, 1), loc="upper left")
plt.show()
def to3d(arr):
arr = np.asarray(arr)
if arr.shape[1] == 3:
return arr
elif arr.shape[1] == 2: # pad with zeros
return np.hstack([arr, np.zeros((arr.shape[0], 1))])
else:
raise ValueError(f"Expected [N,2] or [N,3], got {arr.shape}")
embeddings = [emb_3d, emb_3d_other, emb_3d_cls, emb_3d_meta]
titles = ["t-SNE of MoE-MAE Embeddings",
"t-SNE of Other Embeddings",
"t-SNE of CLS Embeddings",
"t-SNE of Meta Embeddings"]
embeddings = [to3d(e) for e in embeddings]
palette = px.colors.qualitative.T10
color_map = {cls: palette[i % len(palette)] for i, cls in enumerate(label_class)}
fig = make_subplots(
rows=1, cols=4,
specs=[[{"type":"scene"}]*4],
subplot_titles=titles,
horizontal_spacing=0.04
)
for col, (emb, title) in enumerate(zip(embeddings, titles), start=1):
for i in range (len(label_class)):
mask = (labels == i)
pts = emb[mask]
if pts.size == 0:
continue
fig.add_trace(
go.Scatter3d(
x=pts[:, 0], y=pts[:, 1], z=pts[:, 2],
mode="markers",
name=label_class[i],
legendgroup=label_class[i],
showlegend=(col == 1), # show legend only once
marker=dict(size=2, opacity=0.7, color=color_map[label_class[i]]),
hovertemplate=(
f"<b>{title}</b><br>x=%{{x:.3f}}<br>y=%{{y:.3f}}<br>z=%{{z:.3f}}<br>"
f"class={label_class[i]}<extra></extra>"
)
),
row=1, col=col
)
fig.update_layout(
height=500, width=1400,
margin=dict(l=10, r=10, t=40, b=10),
legend=dict(title="Classes", yanchor="top", y=1, xanchor="left", x=1.02)
)
fig.show()
Linear probe performance on EuroSAT-LS Test Split.#
Embedding |
OA % |
Precision (macro) |
Recall (macro) |
F1 (macro) |
|---|---|---|---|---|
CLS token |
78.4 |
0.781 |
0.779 |
0.777 |
All tokens |
84.2 |
0.845 |
0.838 |
0.839 |
All tokens (Avg.) |
74.3 |
0.739 |
0.737 |
0.731 |
3) Expert Specialization#
Data transformation, datasets, and dataloaders#
bigearth_transforms = transforms.Compose(
[
transforms.Resize((40, 40)),
ToFloat(),
ZScoreNormalize(
BigEarthNetInfo.STATISTICS["mean"],
BigEarthNetInfo.STATISTICS["std"],
),
]
)
test_dataset = EuroSATDatasetLS(
root_dir = data_path,
split_file = data_txt_test,
transform=bigearth_transforms,
return_one_hot=True,
strict=False,
)
test_dataloader = DataLoader(
test_dataset,
batch_size=16,
persistent_workers=False,
prefetch_factor=4,
num_workers=4,
shuffle=False,
)
Visualize experts specialities#
data_iter = iter(test_dataloader)
imgs, labels = next(data_iter)
# Pick an image and a layer to inspect
image_index = 3#2#1 #15#13
layer_index = 0
print (label_class[torch.argmax(labels[image_index])])
layer_report_simple(
model,
imgs,
image_index=image_index,
layer_index=layer_index,
max_values=np.array([65454.0, 65454.0, 65330.308]), # From BigEartInfo STATS
rgb_bands=(3,2,1),
device=device
)
AnnualCrop
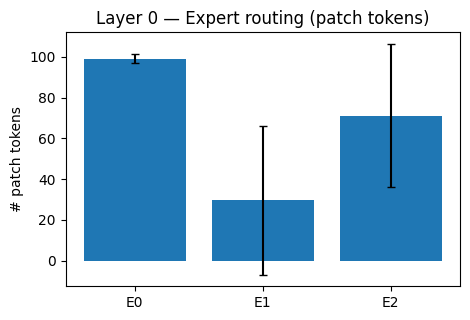
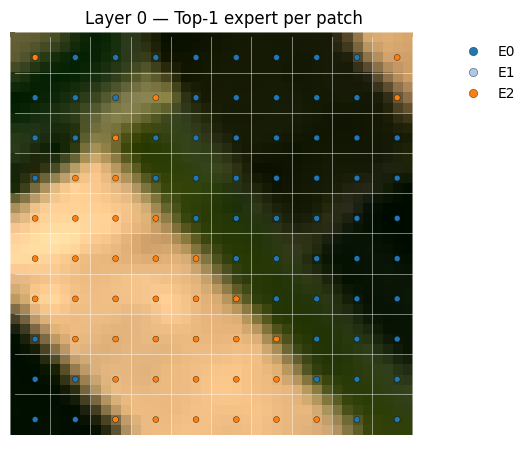
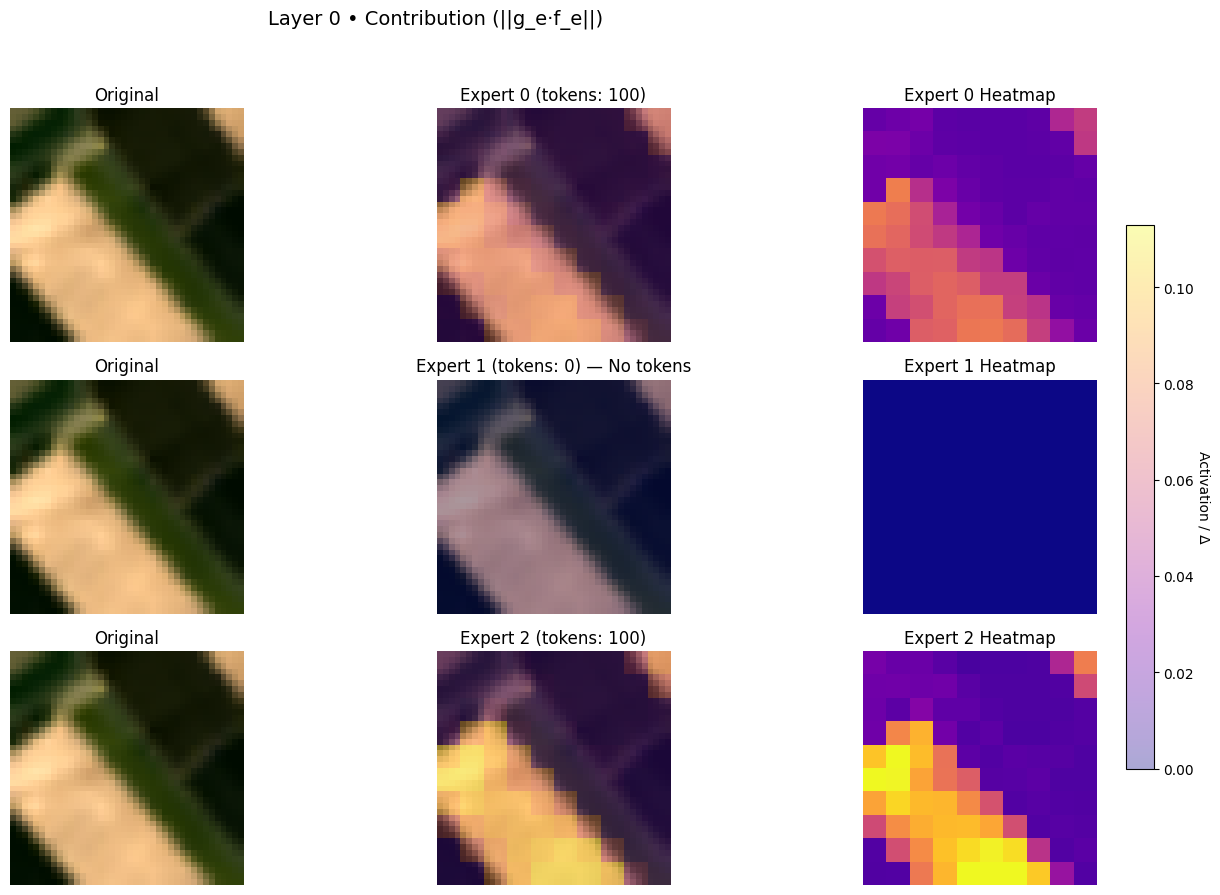

{'num_experts': 3,
'usage_image': array([100, 0, 100]),
'moe_loss': 0.0571892075240612}
4) Image Search with ChromaDB#
MEAN_ARR = np.array([9405.194, 9649.677, 10425.686, 10444.589, 16067.627, 12699.184, 10596.475])
STD_ARR = np.array([6016.344, 6095.472, 5839.462, 6068.493, 6271.440, 4256.046, 3130.776])
MAX_ARR = np.array( [63979.918, 65330.308, 65454.0, 65454.0, 65454.0, 65454.004, 65454.004])
X = x_test
X = X.reshape(X.shape[0],105,144)
Y = y_test
Y = np.argmax(Y,axis=1)
dataset = test_dataset
assert X.ndim == 3 and X.shape[1:] == (105,144)
assert len(Y) == X.shape[0]
N = X.shape[0]
np.random.seed(42)
perm = np.random.permutation(N)
X = X[perm]
Y = Y[perm]
dataset = Subset(dataset, perm)
# Flatten + L2-normalize for cosine
Xf = X.reshape(N, -1)
Xf = Xf / (np.linalg.norm(Xf, axis=1, keepdims=True) + 1e-12)
ids = [f"img_{i}" for i in range(N)]
metas = [{"label": int(Y[i]), "index": int(i)} for i in range(N)]
# ChromDB in memory
client = chromadb.EphemeralClient() # in-memory
col = client.get_or_create_collection(
name="image_embeddings_demo",
metadata={"hnsw:space": "cosine"}
)
# Clear any existing data
try:
col.delete(where={})
except Exception:
pass
col.add(
ids=ids,
embeddings=Xf.tolist(),
metadatas=metas
)
print(f"Loaded {N} vectors into ephemeral Chroma collection.")
Loaded 5400 vectors into ephemeral Chroma collection.
def _query(vec_flat_l2norm: np.ndarray, top_k: int = 5):
res = col.query(
query_embeddings=[vec_flat_l2norm.tolist()],
n_results=top_k,
include=["metadatas","distances"]
)
out = []
for i in range(len(res["ids"][0])):
out.append({
"rank": i+1,
"id": res["ids"][0][i],
"distance": float(res["distances"][0][i]),
"label": int(res["metadatas"][0][i]["label"]),
"index": int(res["metadatas"][0][i]["index"]),
})
return out
def search_by_idx(i: int, top_k: int = 5):
v = Xf[i].astype(np.float32)
return _query(v, top_k)
def search_by_embedding(emb_105x144, top_k: int = 5):
v = torch.as_tensor(emb_105x144).reshape(1, -1).float()
v = v / (v.norm(dim=1, keepdim=True) + 1e-12)
return _query(v[0].cpu().numpy().astype(np.float32), top_k)
def _to_numpy_img(sample,mean_t = MEAN_ARR,std_t = STD_ARR,max_t = MAX_ARR):
img = sample[0]
label = sample[1]
if isinstance(img, torch.Tensor):
img = img.detach().cpu().numpy()
img = np.transpose(img, (1,2,0)) # CHW->HWC
img = img * std_t + mean_t
img = img / max_t
img = np.clip(img, 0, 1)
lo, hi = np.percentile(img, (1, 99))
if hi > lo:
img = np.clip((img - lo) / (hi - lo), 0, 1)
return img[...,1:4][...,[2,1,0]],label
def show_query_and_neighbors(i: int, top_k: int = 5):
rows = search_by_idx(i, top_k=top_k)
print(rows)
cols = min(5, top_k + 1)
grid_rows = 1 + math.ceil(top_k / cols)
plt.figure(figsize=(cols*2.2, grid_rows*2.2))
q,l = _to_numpy_img(dataset[i])
plt.subplot(grid_rows, cols, 1)
plt.imshow(q)
plt.title(f"Query i={i}\nlabel={label_class[int(Y[i])]}")
plt.axis("off")
# Neighbors
for j, r in enumerate(rows, start=1):
pos = 1 + j
if pos > grid_rows * cols: break
n,n_l = _to_numpy_img(dataset[r["index"]])
plt.subplot(grid_rows, cols, pos)
plt.imshow(n)
plt.title(f"i={r['index']}, L={label_class[r['label']]}\nd={r['distance']:.3f}")
plt.axis("off")
plt.tight_layout()
plt.show()
print("Top-5 for idx=0:", search_by_idx(312, top_k=5))
Top-5 for idx=0: [{'rank': 1, 'id': 'img_312', 'distance': 1.1324882507324219e-06, 'label': 7, 'index': 312}, {'rank': 2, 'id': 'img_752', 'distance': 0.15281277894973755, 'label': 0, 'index': 752}, {'rank': 3, 'id': 'img_4297', 'distance': 0.1575269103050232, 'label': 0, 'index': 4297}, {'rank': 4, 'id': 'img_1360', 'distance': 0.1594039797782898, 'label': 7, 'index': 1360}, {'rank': 5, 'id': 'img_2398', 'distance': 0.16025084257125854, 'label': 7, 'index': 2398}]
show_query_and_neighbors(1290, top_k=9)
[{'rank': 1, 'id': 'img_1290', 'distance': 1.1324882507324219e-06, 'label': 0, 'index': 1290}, {'rank': 2, 'id': 'img_4175', 'distance': 0.16615664958953857, 'label': 0, 'index': 4175}, {'rank': 3, 'id': 'img_1877', 'distance': 0.175276517868042, 'label': 0, 'index': 1877}, {'rank': 4, 'id': 'img_1367', 'distance': 0.18707942962646484, 'label': 2, 'index': 1367}, {'rank': 5, 'id': 'img_4402', 'distance': 0.18734389543533325, 'label': 0, 'index': 4402}, {'rank': 6, 'id': 'img_3064', 'distance': 0.19055378437042236, 'label': 0, 'index': 3064}, {'rank': 7, 'id': 'img_1364', 'distance': 0.19418835639953613, 'label': 0, 'index': 1364}, {'rank': 8, 'id': 'img_3528', 'distance': 0.196458101272583, 'label': 0, 'index': 3528}, {'rank': 9, 'id': 'img_5092', 'distance': 0.1973457932472229, 'label': 6, 'index': 5092}]

show_query_and_neighbors(730, top_k=9)
[{'rank': 1, 'id': 'img_730', 'distance': 5.960464477539062e-07, 'label': 8, 'index': 730}, {'rank': 2, 'id': 'img_3212', 'distance': 0.22081124782562256, 'label': 8, 'index': 3212}, {'rank': 3, 'id': 'img_2806', 'distance': 0.23729127645492554, 'label': 8, 'index': 2806}, {'rank': 4, 'id': 'img_4520', 'distance': 0.23889899253845215, 'label': 8, 'index': 4520}, {'rank': 5, 'id': 'img_3732', 'distance': 0.2572094798088074, 'label': 8, 'index': 3732}, {'rank': 6, 'id': 'img_2448', 'distance': 0.275951623916626, 'label': 8, 'index': 2448}, {'rank': 7, 'id': 'img_2877', 'distance': 0.28226345777511597, 'label': 8, 'index': 2877}, {'rank': 8, 'id': 'img_4539', 'distance': 0.28408682346343994, 'label': 8, 'index': 4539}, {'rank': 9, 'id': 'img_3892', 'distance': 0.28518879413604736, 'label': 8, 'index': 3892}]

show_query_and_neighbors(5001, top_k=9)
[{'rank': 1, 'id': 'img_5001', 'distance': 1.0728836059570312e-06, 'label': 9, 'index': 5001}, {'rank': 2, 'id': 'img_3881', 'distance': 0.00280606746673584, 'label': 9, 'index': 3881}, {'rank': 3, 'id': 'img_729', 'distance': 0.002893686294555664, 'label': 9, 'index': 729}, {'rank': 4, 'id': 'img_3226', 'distance': 0.0029290318489074707, 'label': 9, 'index': 3226}, {'rank': 5, 'id': 'img_1019', 'distance': 0.0029552578926086426, 'label': 9, 'index': 1019}, {'rank': 6, 'id': 'img_5352', 'distance': 0.002960801124572754, 'label': 9, 'index': 5352}, {'rank': 7, 'id': 'img_5231', 'distance': 0.0030092597007751465, 'label': 9, 'index': 5231}, {'rank': 8, 'id': 'img_827', 'distance': 0.003015577793121338, 'label': 9, 'index': 827}, {'rank': 9, 'id': 'img_3363', 'distance': 0.003037571907043457, 'label': 9, 'index': 3363}]

show_query_and_neighbors(267, top_k=9)
[{'rank': 1, 'id': 'img_267', 'distance': 7.748603820800781e-07, 'label': 8, 'index': 267}, {'rank': 2, 'id': 'img_1909', 'distance': 0.11097675561904907, 'label': 9, 'index': 1909}, {'rank': 3, 'id': 'img_1583', 'distance': 0.11748170852661133, 'label': 9, 'index': 1583}, {'rank': 4, 'id': 'img_2906', 'distance': 0.11759030818939209, 'label': 9, 'index': 2906}, {'rank': 5, 'id': 'img_2451', 'distance': 0.11840802431106567, 'label': 9, 'index': 2451}, {'rank': 6, 'id': 'img_1926', 'distance': 0.12580817937850952, 'label': 9, 'index': 1926}, {'rank': 7, 'id': 'img_2180', 'distance': 0.12865948677062988, 'label': 9, 'index': 2180}, {'rank': 8, 'id': 'img_5202', 'distance': 0.12914586067199707, 'label': 9, 'index': 5202}, {'rank': 9, 'id': 'img_1658', 'distance': 0.13448363542556763, 'label': 9, 'index': 1658}]

show_query_and_neighbors(315, top_k=9)
[{'rank': 1, 'id': 'img_315', 'distance': 1.7285346984863281e-06, 'label': 1, 'index': 315}, {'rank': 2, 'id': 'img_3527', 'distance': 0.06591832637786865, 'label': 1, 'index': 3527}, {'rank': 3, 'id': 'img_3233', 'distance': 0.07000815868377686, 'label': 1, 'index': 3233}, {'rank': 4, 'id': 'img_3805', 'distance': 0.07623088359832764, 'label': 1, 'index': 3805}, {'rank': 5, 'id': 'img_3422', 'distance': 0.07806098461151123, 'label': 1, 'index': 3422}, {'rank': 6, 'id': 'img_875', 'distance': 0.08080369234085083, 'label': 1, 'index': 875}, {'rank': 7, 'id': 'img_3668', 'distance': 0.08265680074691772, 'label': 1, 'index': 3668}, {'rank': 8, 'id': 'img_4212', 'distance': 0.08279412984848022, 'label': 1, 'index': 4212}, {'rank': 9, 'id': 'img_128', 'distance': 0.08339214324951172, 'label': 1, 'index': 128}]

show_query_and_neighbors(421, top_k=9)
[{'rank': 1, 'id': 'img_421', 'distance': 1.0728836059570312e-06, 'label': 7, 'index': 421}, {'rank': 2, 'id': 'img_752', 'distance': 0.12855345010757446, 'label': 0, 'index': 752}, {'rank': 3, 'id': 'img_4297', 'distance': 0.12946921586990356, 'label': 0, 'index': 4297}, {'rank': 4, 'id': 'img_3552', 'distance': 0.13634300231933594, 'label': 7, 'index': 3552}, {'rank': 5, 'id': 'img_418', 'distance': 0.1376885175704956, 'label': 7, 'index': 418}, {'rank': 6, 'id': 'img_1418', 'distance': 0.14496833086013794, 'label': 7, 'index': 1418}, {'rank': 7, 'id': 'img_1360', 'distance': 0.1458379030227661, 'label': 7, 'index': 1360}, {'rank': 8, 'id': 'img_1059', 'distance': 0.14881408214569092, 'label': 2, 'index': 1059}, {'rank': 9, 'id': 'img_1933', 'distance': 0.14977967739105225, 'label': 7, 'index': 1933}]

show_query_and_neighbors(697, top_k=9)
[{'rank': 1, 'id': 'img_697', 'distance': -9.5367431640625e-07, 'label': 0, 'index': 697}, {'rank': 2, 'id': 'img_195', 'distance': 0.3298208713531494, 'label': 0, 'index': 195}, {'rank': 3, 'id': 'img_1839', 'distance': 0.36086398363113403, 'label': 5, 'index': 1839}, {'rank': 4, 'id': 'img_4737', 'distance': 0.36322879791259766, 'label': 0, 'index': 4737}, {'rank': 5, 'id': 'img_2999', 'distance': 0.3649284243583679, 'label': 0, 'index': 2999}, {'rank': 6, 'id': 'img_2519', 'distance': 0.36681413650512695, 'label': 0, 'index': 2519}, {'rank': 7, 'id': 'img_1994', 'distance': 0.36947381496429443, 'label': 0, 'index': 1994}, {'rank': 8, 'id': 'img_664', 'distance': 0.3759034276008606, 'label': 5, 'index': 664}, {'rank': 9, 'id': 'img_5208', 'distance': 0.37995588779449463, 'label': 0, 'index': 5208}]
