Parallel computing with Dask
Contents
Parallel computing with Dask#
Context#
We will be using Dask with Xarray to parallelize our data analysis. The analysis is very similar to what we have done in previous episodes but this time we will use data on a global coverage that we read from a shared catalog (stored online in the Pangeo EOSC Openstack Object Storage).
Data#
In this episode, we will be using CMIP6 data from intake-esm catalogue
Setup#
This episode uses the following Python packages:
pooch [USR+20]
s3fs [S3FsDTeam16]
hvplot [RSB+20]
dask [DaskDTeam16]
graphviz [EGK+03]
numpy [HMvdW+20]
pandas [pdt20]
geopandas [JdBF+20]
Please install these packages if not already available in your Python environment (you might want to take a look at the Setup page of the tutorial).
Packages#
In this episode, Python packages are imported when we start to use them. However, for best software practices, we recommend you to install and import all the necessary libraries at the top of your Jupyter notebook.
Parallelize with Dask#
We know from previous chapter chunking_introduction that chunking is key for analyzing large datasets. In this episode, we will learn to parallelize our data analysis using Dask on our chunked dataset.
What is Dask ?#
Dask scales the existing Python ecosystem: with very or no changes in your code, you can speed-up computation using Dask or process bigger than memory datasets.
Dask is a flexible library for parallel computing in Python.
It is widely used for handling large and complex Earth Science datasets and speed up science.
Dask is powerful, scalable and flexible. It is the leading platform today for data analytics at scale.
It scales natively to clusters, cloud, HPC and bridges prototyping up to production.
The strength of Dask is that is scales and accelerates the existing Python ecosystem e.g. Numpy, Pandas and Scikit-learn with few effort from end-users.
It is interesting to note that at first, Dask has been created to handle data that is larger than memory, on a single computer. It then was extended with Distributed to compute data in parallel over clusters of computers.
How does Dask scale and accelerate your data analysis?#
Dask proposes different abstractions to distribute your computation. In this Dask Introduction section, we will focus on Dask Array which is widely used in pangeo ecosystem as a back end of Xarray.
As shown in the previous section Dask Array is based on chunks. Chunks of a Dask Array are well-known Numpy arrays. By transforming our big datasets to Dask Array, making use of chunk, a large array is handled as many smaller Numpy ones and we can compute each of these chunks independently.

- `Xarray` uses Dask Arrays instead of Numpy when chunking is enabled, and thus all Xarray operations are performed through Dask, which enables distributed processing.
How does Xarray with Dask distribute data analysis?#
When we use chunks with Xarray, the real computation is only done when needed or asked for, usually when invoking compute() function. Dask generates a task graph describing the computations to be done. When using Dask Distributed a Scheduler distributes these tasks across several Workers.
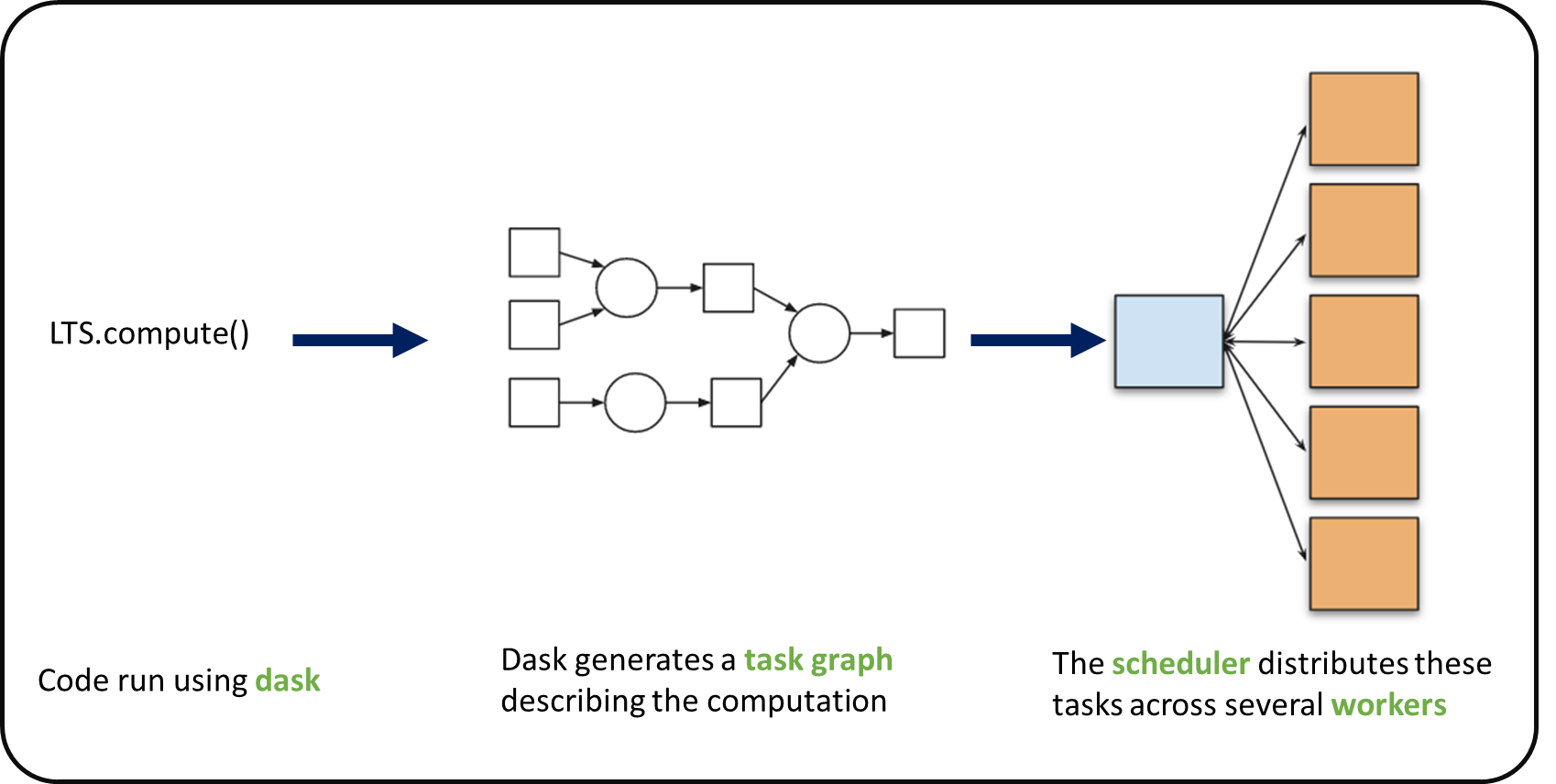
#### What is a Dask Distributed ?
A Dask Distributed is made of two main components:
a Scheduler, responsible for dishandling computations graph and distributing tasks to Workers.
One or several (up to 1000s) Workers, computing individual tasks and storing results and data into distributed memory (RAM and/or worker’s local disk).
A user usually needs distributed Client and Cluster object as shown below to use Dask Distribute.

Where can we deploy Dask distributed cluster?#
Dask distributed clusters can be deployed on your laptop or on distributed infrastructures ( Cloud, HPC centers or ..). Dask distributed Cluster object is responsible of deploying and scaling a Dask Cluster on the underlying resources.

Tip
A Dask Cluster can also be created on a single machine (for instance your laptop) e.g. there is no need to have dedicated computational resources. However, speedup will only be limited to your single machine resources if you do not have dedicated computational resources!
Dask distributed Client#
The Dask distributed Client is what allows you to interact with Dask distributed Clusters. When using Dask distributed, you always need to create a Client object. Once a Client has been created, it will be used by default by each call to a Dask API, even if you do not explicitly use it.
No matter the Dask API (e.g. Arrays, Dataframes, Delayed, Futures, etc.) that you use, under the hood, Dask will create a Directed Acyclic Graph (DAG) of tasks by analysing the code. Client will be responsible to submit this DAG to the Scheduler along with the final result you want to compute. The Client will also gather results from the Workers, and aggregates it back in its underlying Python process.
Using Client() function with no argument, you will create a local Dask cluster with a number of workers and threads per worker corresponding to the number of cores in the ‘local’ machine. Here, during the workshop, we are running this notebook in Pangeo EOSC cloud deployment, so the ‘local’ machine is the jupyterlab you are using at the Cloud, and the number of cores is the number of cores on the cloud computing resources you’ve been given (not on your laptop).
from dask.distributed import Client
client = Client() # create a local dask cluster on the local machine.
client
Client
Client-e4a7e191-49bf-11ed-8fb1-56384af59625
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
bc09e969
| Dashboard: http://127.0.0.1:8787/status | Workers: 4 |
| Total threads: 4 | Total memory: 8.00 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-4e5a2acd-4da8-42b4-9c20-f83fb888a434
| Comm: tcp://127.0.0.1:41239 | Workers: 4 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 4 |
| Started: Just now | Total memory: 8.00 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:37793 | Total threads: 1 |
| Dashboard: http://127.0.0.1:38349/status | Memory: 2.00 GiB |
| Nanny: tcp://127.0.0.1:44709 | |
| Local directory: /tmp/dask-worker-space/worker-mfu2k8v0 | |
Worker: 1
| Comm: tcp://127.0.0.1:41179 | Total threads: 1 |
| Dashboard: http://127.0.0.1:32949/status | Memory: 2.00 GiB |
| Nanny: tcp://127.0.0.1:36831 | |
| Local directory: /tmp/dask-worker-space/worker-9n_oqci4 | |
Worker: 2
| Comm: tcp://127.0.0.1:35585 | Total threads: 1 |
| Dashboard: http://127.0.0.1:35711/status | Memory: 2.00 GiB |
| Nanny: tcp://127.0.0.1:41189 | |
| Local directory: /tmp/dask-worker-space/worker-x0yeahfi | |
Worker: 3
| Comm: tcp://127.0.0.1:46195 | Total threads: 1 |
| Dashboard: http://127.0.0.1:37175/status | Memory: 2.00 GiB |
| Nanny: tcp://127.0.0.1:34495 | |
| Local directory: /tmp/dask-worker-space/worker-gfhaw_kc | |
Inspecting the Cluster Info section above gives us information about the created cluster: we have 2 or 4 workers and the same number of threads (e.g. 1 thread per worker).
- You can also create a local cluster with the `LocalCluster` constructor and use `n_workers` and `threads_per_worker` to manually specify the number of processes and threads you want to use. For instance, we could use `n_workers=2` and `threads_per_worker=2`.
- This is sometimes preferable (in terms of performance), or when you run this tutorial on your PC, you can avoid dask to use all your resources you have on your PC!
Dask Dashboard#
Dask comes with a really handy interface: the Dask Dashboard. We will learn here, how to use that through dask jupyterlab extension.
To use Dask Dashbord through jupyterlab extension at Pangeo EOSC FOSS4G infrastructure, you will just need too look at the html link you have for your jupyterlab, and Dask dashboard port number, as highlighted in the figure below.


Then click the orange icon indicated in the above figure, and type ‘your’ dashboard link (normally, you just need to replace ‘todaka’ to ‘your username’).
You can click several buttons indicated with blue arrows in above figures, then drag and drop to place them as your convenience.

It’s really helpfull to understand your computation and how it is distributed.
Dask Distributed computations on our dataset#
Lets open dataset from catalogue we made before, select a single location over time and visualize the task graph generated by Dask, and observe the Dask Dashboard.
Read from online cmip6 ARCO dataset#
We will access analysis-ready, cloud optimized (ARCO) introduced in previous data_discovery section.
import xarray as xr
xr.set_options(display_style='html')
import intake
import cftime
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import numpy as np
import hvplot.xarray
%matplotlib inline
cat_url = "https://storage.googleapis.com/cmip6/pangeo-cmip6.json"
col = intake.open_esm_datastore(cat_url)
cat = col.search(experiment_id=['historical']
#, table_id=['day']
#source_id=['NorESM2-LM']
,institution_id =['NIMS-KMA']
#, table_id=['Amon']
, table_id=['3hr']
, variable_id=['tas'], member_id=['r1i1p1f1']
,grid_label=['gr'])
display(cat.df)
dset_dict = cat.to_dataset_dict(zarr_kwargs={'use_cftime':True})
dset = dset_dict[list(dset_dict.keys())[0]]
| activity_id | institution_id | source_id | experiment_id | member_id | table_id | variable_id | grid_label | zstore | dcpp_init_year | version | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CMIP | NIMS-KMA | KACE-1-0-G | historical | r1i1p1f1 | 3hr | tas | gr | gs://cmip6/CMIP6/CMIP/NIMS-KMA/KACE-1-0-G/hist... | NaN | 20190913 |
--> The keys in the returned dictionary of datasets are constructed as follows:
'activity_id.institution_id.source_id.experiment_id.table_id.grid_label'
dset
<xarray.Dataset>
Dimensions: (lat: 144, bnds: 2, lon: 192, member_id: 1, time: 475200)
Coordinates:
height float64 ...
* lat (lat) float64 -89.38 -88.12 -86.88 -85.62 ... 86.88 88.12 89.38
lat_bnds (lat, bnds) float64 dask.array<chunksize=(144, 2), meta=np.ndarray>
* lon (lon) float64 0.9375 2.812 4.688 6.562 ... 355.3 357.2 359.1
lon_bnds (lon, bnds) float64 dask.array<chunksize=(192, 2), meta=np.ndarray>
* time (time) object 1850-01-01 01:30:00 ... 2014-12-30 22:30:00
time_bnds (time, bnds) object dask.array<chunksize=(59400, 1), meta=np.ndarray>
* member_id (member_id) <U8 'r1i1p1f1'
Dimensions without coordinates: bnds
Data variables:
tas (member_id, time, lat, lon) float32 dask.array<chunksize=(1, 856, 144, 192), meta=np.ndarray>
Attributes: (12/52)
Conventions: CF-1.7 CMIP-6.2
NCO: netCDF Operators version 4.7.5 (Homepage = http:...
activity_id: CMIP
branch_method: standard
branch_time_in_child: 0.0
branch_time_in_parent: 109500.0
... ...
variable_id: tas
variant_label: r1i1p1f1
netcdf_tracking_ids: hdl:21.14100/7337562e-b296-4bb7-a794-6ebeb148959...
version_id: v20190913
intake_esm_varname: ['tas']
intake_esm_dataset_key: CMIP.NIMS-KMA.KACE-1-0-G.historical.3hr.grCompute Weigted arctic average#
Let’s try to also take only the data above 60\(^\circ\)
dset=dset.where(dset['lat']>60.,drop=True)#.sel(time=slice('2000-01-01', '2010-01-01'))
dset
<xarray.Dataset>
Dimensions: (member_id: 1, time: 475200, lat: 24, lon: 192, bnds: 2)
Coordinates:
height float64 2.0
* lat (lat) float64 60.62 61.88 63.12 64.38 ... 85.62 86.88 88.12 89.38
lat_bnds (lat, bnds) float64 dask.array<chunksize=(24, 2), meta=np.ndarray>
* lon (lon) float64 0.9375 2.812 4.688 6.562 ... 355.3 357.2 359.1
lon_bnds (lon, bnds) float64 dask.array<chunksize=(192, 2), meta=np.ndarray>
* time (time) object 1850-01-01 01:30:00 ... 2014-12-30 22:30:00
time_bnds (time, bnds) object dask.array<chunksize=(59400, 1), meta=np.ndarray>
* member_id (member_id) <U8 'r1i1p1f1'
Dimensions without coordinates: bnds
Data variables:
tas (member_id, time, lat, lon) float32 dask.array<chunksize=(1, 856, 24, 192), meta=np.ndarray>
Attributes: (12/52)
Conventions: CF-1.7 CMIP-6.2
NCO: netCDF Operators version 4.7.5 (Homepage = http:...
activity_id: CMIP
branch_method: standard
branch_time_in_child: 0.0
branch_time_in_parent: 109500.0
... ...
variable_id: tas
variant_label: r1i1p1f1
netcdf_tracking_ids: hdl:21.14100/7337562e-b296-4bb7-a794-6ebeb148959...
version_id: v20190913
intake_esm_varname: ['tas']
intake_esm_dataset_key: CMIP.NIMS-KMA.KACE-1-0-G.historical.3hr.grBy inspecting the variable ‘tas’ on the representation above, you’ll see that data array represent about 8.2 GiB of data, so more thant what is available on this notebook server, i.e. even on the local Dask Cluster we created above. But thanks to chunking, we can still analyze it!
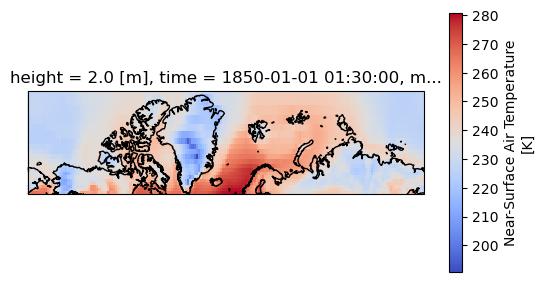
Lets plot the first timestep
projection = ccrs.Mercator(central_longitude=-10)
f, ax = plt.subplots(subplot_kw=dict(projection=projection))
dset['tas'].isel(time=0).plot(transform=ccrs.PlateCarree(), cbar_kwargs=dict(shrink=0.7), cmap='coolwarm')
ax.coastlines()
<cartopy.mpl.feature_artist.FeatureArtist at 0x7f558a984be0>
Compute weighted mean#
Creating weights: for a rectangular grid the cosine of the latitude is proportional to the grid cell area.
Compute weighted mean values
def computeWeightedMean(ds):
# Compute weights based on the xarray you pass
weights = np.cos(np.deg2rad(ds.lat))
weights.name = "weights"
# Compute weighted mean
air_weighted = ds.weighted(weights)
weighted_mean = air_weighted.mean(("lon", "lat"))
return weighted_mean
weighted_mean = computeWeightedMean(dset)
weighted_mean
<xarray.Dataset>
Dimensions: (time: 475200, member_id: 1)
Coordinates:
height float64 2.0
* time (time) object 1850-01-01 01:30:00 ... 2014-12-30 22:30:00
* member_id (member_id) <U8 'r1i1p1f1'
Data variables:
tas (member_id, time) float64 dask.array<chunksize=(1, 856), meta=np.ndarray>Did you notice something on the Dask Dashboard when running the two previous cells?
We didn’t ‘compute’ anything. We just build a Dask task graph with it’s size indicated as count above, but did not ask Dask to return a result.
You can try to plot the dask graph before computation and understand what dask workers will do to compute the value we asked for.
weighted_mean.tas.data.visualize()
dot: graph is too large for cairo-renderer bitmaps. Scaling by 0.146366 to fit

Lets compute using dask!#
%%time
weighted_mean=weighted_mean.compute()
2022-10-11 23:59:15,181 - distributed.worker_memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 1.23 GiB -- Worker memory limit: 2.00 GiB
2022-10-11 23:59:31,158 - distributed.worker_memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 1.23 GiB -- Worker memory limit: 2.00 GiB
2022-10-12 00:00:23,293 - distributed.worker_memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 1.24 GiB -- Worker memory limit: 2.00 GiB
2022-10-12 00:00:38,871 - distributed.worker_memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 1.33 GiB -- Worker memory limit: 2.00 GiB
CPU times: user 58 s, sys: 3.51 s, total: 1min 1s
Wall time: 4min 17s
Calling compute on our Xarray object triggered the execution on Dask Cluster side.
You should be able to see how Dask is working on Dask Dashboard.
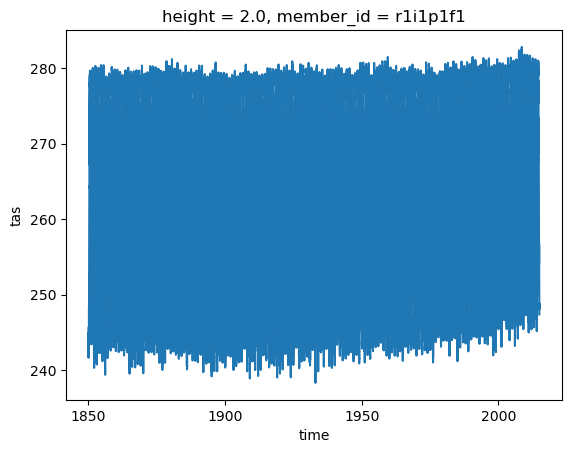
weighted_mean.tas.plot()
[<matplotlib.lines.Line2D at 0x7f5593012970>]
Close client to terminate local dask cluster#
The Client and associated LocalCluster object will be automatically closed when your Python session ends. When using Jupyter notebooks, we recommend to close it explicitely whenever you are done with your local Dask cluster.
client.close()
Scaling your Computation using Dask Gateway.#
For this workshop, according to the Pangeo EOSC deployment, you will learn how to use Dask Gateway to manage Dask clusters over Kubernetes, allowing to run our data analysis in parallel e.g. distribute tasks across several workers.
Lets set up your Dask Gateway.
As Dask Gateway is configured by default on this ifnrastructure, you just need to execute the following cells.
from dask_gateway import Gateway
gateway = Gateway()
##A line of trick to clean your dask cluster before you start your computation
from dask.distributed import Client
clusters=gateway.list_clusters()
print(clusters )
for cluster in clusters :
cluster= gateway.connect(cluster.name)
print(cluster)
client = Client(cluster)
client.close()
cluster.shutdown()
[]
Create a new Dask cluster with the Dask Gateway#
## Please don't execute this cell, it is needed for building the Jupyter Book
cluster = None
cluster = gateway.new_cluster(worker_memory=2, worker_cores=1)
cluster.scale(8)
cluster
Lets setup the Dask Dashboard with your new cluster.
This time, copy and past the link above indicated in Dashboard to the dasklab extension.
Get a client from the Dask Gateway Cluster#
As stated above, creating a Dask Client is mandatory in order to perform following Daks computations on your Dask Cluster.
from distributed import Client
if cluster:
client = Client(cluster) # create a dask Gateway cluster
else:
client = Client() # create a local dask cluster on the machine.
client
Client
Client-0f6f185d-49c1-11ed-8fb1-56384af59625
| Connection method: Cluster object | Cluster type: dask_gateway.GatewayCluster |
| Dashboard: /jupyterhub/services/dask-gateway/clusters/daskhub.96da6a283dbf4bbd9f38572e34faeed9/status |
Cluster Info
GatewayCluster
- Name: daskhub.96da6a283dbf4bbd9f38572e34faeed9
- Dashboard: /jupyterhub/services/dask-gateway/clusters/daskhub.96da6a283dbf4bbd9f38572e34faeed9/status
Repeat above computation with more dask workers.#
dset
<xarray.Dataset>
Dimensions: (member_id: 1, time: 475200, lat: 24, lon: 192, bnds: 2)
Coordinates:
height float64 2.0
* lat (lat) float64 60.62 61.88 63.12 64.38 ... 85.62 86.88 88.12 89.38
lat_bnds (lat, bnds) float64 dask.array<chunksize=(24, 2), meta=np.ndarray>
* lon (lon) float64 0.9375 2.812 4.688 6.562 ... 355.3 357.2 359.1
lon_bnds (lon, bnds) float64 dask.array<chunksize=(192, 2), meta=np.ndarray>
* time (time) object 1850-01-01 01:30:00 ... 2014-12-30 22:30:00
time_bnds (time, bnds) object dask.array<chunksize=(59400, 1), meta=np.ndarray>
* member_id (member_id) <U8 'r1i1p1f1'
Dimensions without coordinates: bnds
Data variables:
tas (member_id, time, lat, lon) float32 dask.array<chunksize=(1, 856, 24, 192), meta=np.ndarray>
Attributes: (12/52)
Conventions: CF-1.7 CMIP-6.2
NCO: netCDF Operators version 4.7.5 (Homepage = http:...
activity_id: CMIP
branch_method: standard
branch_time_in_child: 0.0
branch_time_in_parent: 109500.0
... ...
variable_id: tas
variant_label: r1i1p1f1
netcdf_tracking_ids: hdl:21.14100/7337562e-b296-4bb7-a794-6ebeb148959...
version_id: v20190913
intake_esm_varname: ['tas']
intake_esm_dataset_key: CMIP.NIMS-KMA.KACE-1-0-G.historical.3hr.grweighted_mean = computeWeightedMean(dset)
weighted_mean
<xarray.Dataset>
Dimensions: (time: 475200, member_id: 1)
Coordinates:
height float64 2.0
* time (time) object 1850-01-01 01:30:00 ... 2014-12-30 22:30:00
* member_id (member_id) <U8 'r1i1p1f1'
Data variables:
tas (member_id, time) float64 dask.array<chunksize=(1, 856), meta=np.ndarray>%%time
weighted_mean=weighted_mean.compute()
CPU times: user 1.48 s, sys: 115 ms, total: 1.6 s
Wall time: 2min
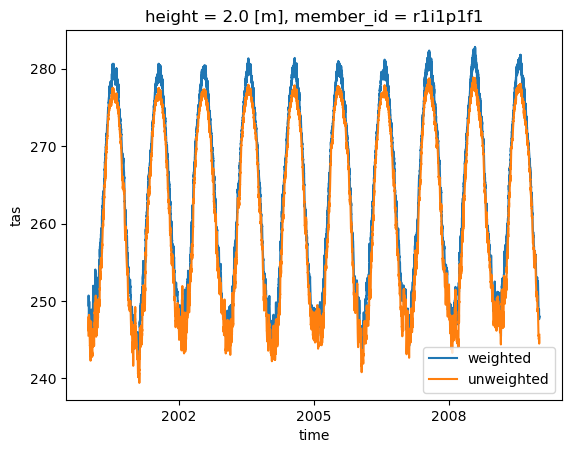
Comparison with unweighted mean#
We select a time range
Note how the weighted mean temperature is higher than the unweighted.
weighted_mean['tas'].sel(time=slice('2000-01-01', '2010-01-01')
).plot(label="weighted")
dset['tas'].sel(time=slice('2000-01-01', '2010-01-01')
).mean(("lon", "lat")).plot(label="unweighted")
plt.legend()
<matplotlib.legend.Legend at 0x7f5594b11c10>
- It was faster. Why?
hvplot and dask#
dset.isel(#time=0,
member_id=0).hvplot.quadmesh(x='lon', y='lat'
, rasterize=True
, geo=True
, global_extent=False
, projection=ccrs.Orthographic(30, 90)
, project=True
, cmap='coolwarm'
, coastline='50m'
, frame_width=400
, title=dset.attrs['references']
#, title="Near-surface Temperature over Norway (CMIP6 CESM2)"
)
WARNING:param.main: Calling the .opts method with options broken down by options group (i.e. separate plot, style and norm groups) is deprecated. Use the .options method converting to the simplified format instead or use hv.opts.apply_groups for backward compatibility.